Sponsored Post
 Simulating the physics of fluid flow must stand as the classic scientific high-performance computing application. These problems include everything from calculating global weather patterns to the air flowing around a space shuttle during re-entry. Solving the numerical equations that describe fluid flow would be impossible without high performance computing (HPC) platforms. Researchers using the latest Intel Xeon® processors and Intel MPI software can achieve the extreme performance essential for these computational fluid dynamics (CFD) solutions.
Simulating the physics of fluid flow must stand as the classic scientific high-performance computing application. These problems include everything from calculating global weather patterns to the air flowing around a space shuttle during re-entry. Solving the numerical equations that describe fluid flow would be impossible without high performance computing (HPC) platforms. Researchers using the latest Intel Xeon® processors and Intel MPI software can achieve the extreme performance essential for these computational fluid dynamics (CFD) solutions.
Key to nearly all CFD applications are the Navier-Stokes equations, a set of non-linear, partial-differential equations describing the mass, momentum, and energy conservation in a flowing fluid. The solution of these equations represents a field where the flow velocity and direction is defined at every point in a region of space within an interval of time. It is from this velocity field that other quantities, such as pressure or temperature, can be calculated.[clickToTweet tweet=”Using Intel® Xeon® Scalable processor, optimized math library, and MPI helps HiFUN solver attain super-linear performance. ” quote=”Using Intel Xeon Scalable processor, optimized math library, and MPI helps HiFUN solver attain super-linear performance. “]
But the complex geometry and physics inherent in a typical industrial application can quite easily result in an algebraic system of millions of equations that need to be solved. Which is why such problems require a large-scale, massively parallel supercomputer to return accurate results within a reasonable timeframe. The HiFUN* solver, from Simulation and Innovation (SandI) Engineering Solutions, is a CFD application that is designed to take full advantage of such massively parallel HPC platforms.
Developers recently demonstrated that HiFUN can scale to over 10,000 Intel Xeon processor cores on the NASA Pleiades supercomputer used to study the design of the NASA Trap Wing. HiFUN shows a near-ideal speedup for 4,096 processor cores. For 7,168 processor cores on Pleiades, HiFUN attained a parallel efficiency of about 88%. Even for 10,248 processor cores over a modest grid size of about 63.5 million volumes, HiFUN offers reasonable parallel efficiency of about 75%. This scalable parallel performance of HiFUN is a boon to NASA designers because they can expect to have a turnaround time independent of the problem size.
In a study that compared the single-node performance of the HiFUN solver on the Intel Xeon E5-2697 v4 processor, with 18 cores, against performance on the Intel Xeon Scalable processor Gold 6148, with 20 cores, the solver showed a performance gain on the Intel Xeon Scalable processor of about 22%. This is due not only to the extra processor cores, but to the larger L2 cache, higher memory speed, and higher memory bandwidth from the increased number of memory channels in the Intel Xeon Scalable processor.
Table 1. Processors comparison
| Features | Intel Xenon Processor | Intel Xenon Scalable Processor |
| Processor | Intel Xeon E5-2697 v4 processor | Intel Xeon Scalable processor Gold 6148 |
| Cores per socket | 18 | 20 |
| Speed | 2.3 GHz | 2.4 GHz |
| Cache (L2/L3) | 256 KB/45 MB | 1 MB/27 MB |
| Memory size | 128 GB | 192 GB |
| Memory speed | 2,400 MHz | 2,666 MHz |
| Memory channels | 4 | 6 |
Clearly, the higher core density of the Intel Xeon Scalable processor leads to improved intra-node parallel performance, creating a compact parallel cluster for a given number of processor cores.
Comparing the ideal and actual speedup curves obtained using the HiFUN solver, we can see in Figure 1 that as the number of nodes increases, the actual speedup becomes increasingly higher compared to the ideal speedup.
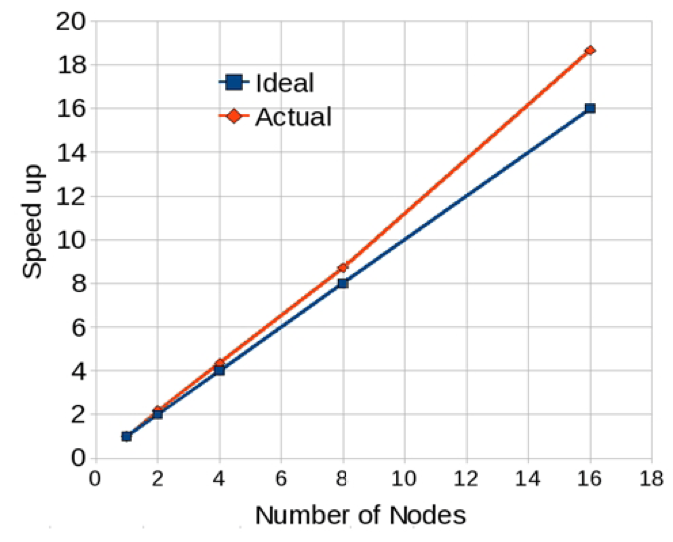
Figure 1 – Speedup of HiFUN on a multi-node Intel processor-based cluster
The HiFUN solver shows that the latest-generation Intel Xeon Scalable processor enhances the single-node performance due to the availability of large cache, higher core density per CPU, higher memory speed, and larger memory bandwidth. The higher core density improves intra-node parallel performance that permits users to build more compact clusters for a given number of processor cores.
The HiFUN solver can exploit better cache utilization that contributes to the super-linear performance gained through the combination of a high-performance interconnect between nodes and the highly-optimized Intel® MPI Library.

