
This guest post from IBM walks readers through the complexities of the data pipeline for connected cars, and how to address these challenges and storage questions.

(Photo: Shutterstock/Just Super)
A connected car is defined as a vehicle that can communicate with external entities such as traffic signals, satellites, pedestrians, and other vehicles, among others. There are two key connected car use cases:
- Advanced Driver Assistance Systems (ADAS) delivering services like navigation and remote diagnostics.
- Autonomous Driving (AD) with services like auto parking, auto pilot, and more.
A connected car can generate up to a gigabyte of data per day, and perhaps even more. Impressively, it is estimated that there are approximately 2 million connected cars on our roadways at this very moment. This means the storage demands can be up to 200 exabytes per day. It goes without saying: This is an incredible and overwhelming amount of data. In fact, for a car used in generating data for training an ADAS/AD artificial intelligence (AI) model, this number jumps to potentially terabytes of data per day.
We touched on the challenges and needs around managing, searching and tagging this data for the autonomous driving space in the first part of this series on insideHPC, Solving the Data Management Challenge of Autonomous Driving.
We will now explore a meta-framework IBM has developed to illustrate the data pipeline for ADAS/AD use cases. It should be noted: This pattern was developed by working with numerous customers, helping to build the infrastructure needed to handle their data and AI challenges, as well as conversations with top analysts watching this space.
Explaining the importance of having a meta-framework for ADAS/AD is simple – production-grade AI is messy and difficult to implement, let alone illustrate for the purposes of strategic IT planning. As we discussed previously, the sheer amount and variety of data and the quality of that data is crucial for the success of AI projects. And as organizations move from experimentation and prototyping to deploying AI in production, the first challenge is to embed AI into the existing data pipeline and build a data pipeline that can leverage existing and new data repositories.
A connected car can generate up to a gigabyte of data per day, and perhaps even more.
There are three phases to the AI data pipeline for ADAS/AD:
- The ingest of mixed data, primarily unstructured, with raw throughput
- The classification of metadata including tagging and ETL (extract, transform, load) with random I/O
- The analysis/training of the data which is GPU driven; includes computing with requirements for low latency and random read throughput
A data scientist’s productivity is dependent upon the efficacy of all the phases in the data pipeline, as well as the performance of the infrastructure used for running AI workloads. And underlying storage technologies play a crucial role in both these aspects.
The following diagram illustrates the meta-framework developed by IBM to handle ADAS/AS workflows, with storage requirements indicated for each stage in the pipeline. (Right click the image to open in a new tab to view enlarged diagram):
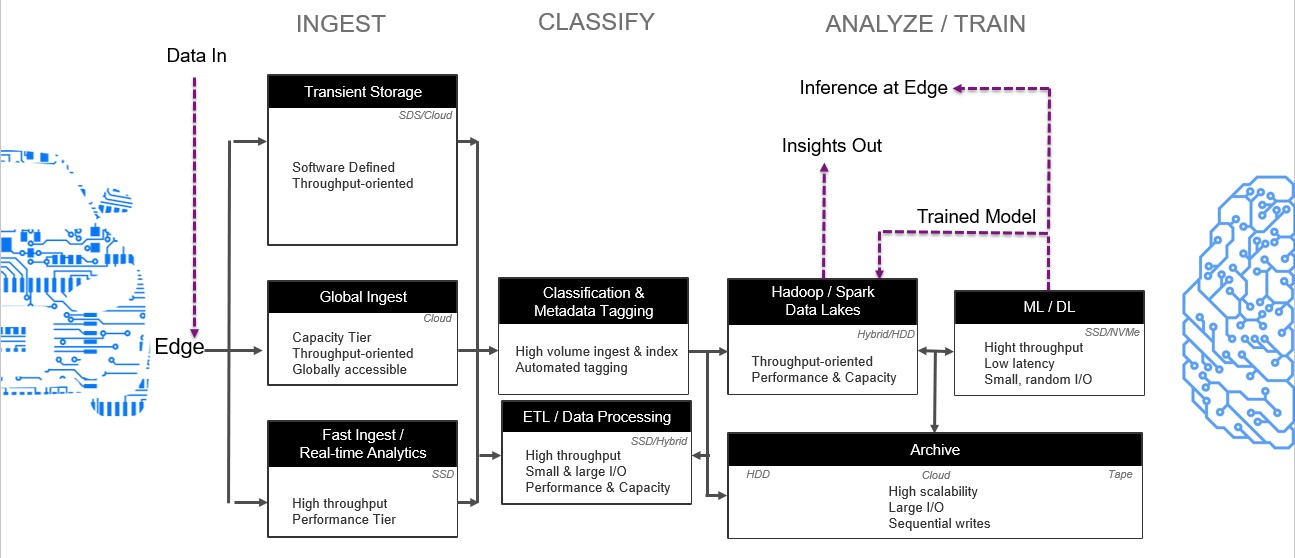
When we think about this pipeline, the IBM Storage portfolio provides advantage and value at every stage. IBM has a comprehensive portfolio of software-defined storage products that enable customers to build their data pipelines with the right performance and cost characteristics for each stage.
This includes IBM Cloud Object Storage at the edge for global ingest and geographically dispersed repositories and a variety of different Elastic Storage Server models powered by IBM Spectrum Scale, for high performance file storage and a scalable common data lakes. This also includes IBM Spectrum Archive which enables direct file access to data stored on tape for very affordable archives. And, finally, a brand-new addition to this portfolio, IBM Spectrum Discover – a modern metadata management software that provides data insight at petabyte scale for unstructured data. IBM Spectrum Discover easily connects to IBM Cloud Object Storage and IBM Spectrum Scale to rapidly ingest, consolidate and index metadata for billions of files and objects.
Take a look at how these IBM products fit into the pipeline below (Right click the image to open in a new tab to view enlarged diagram):
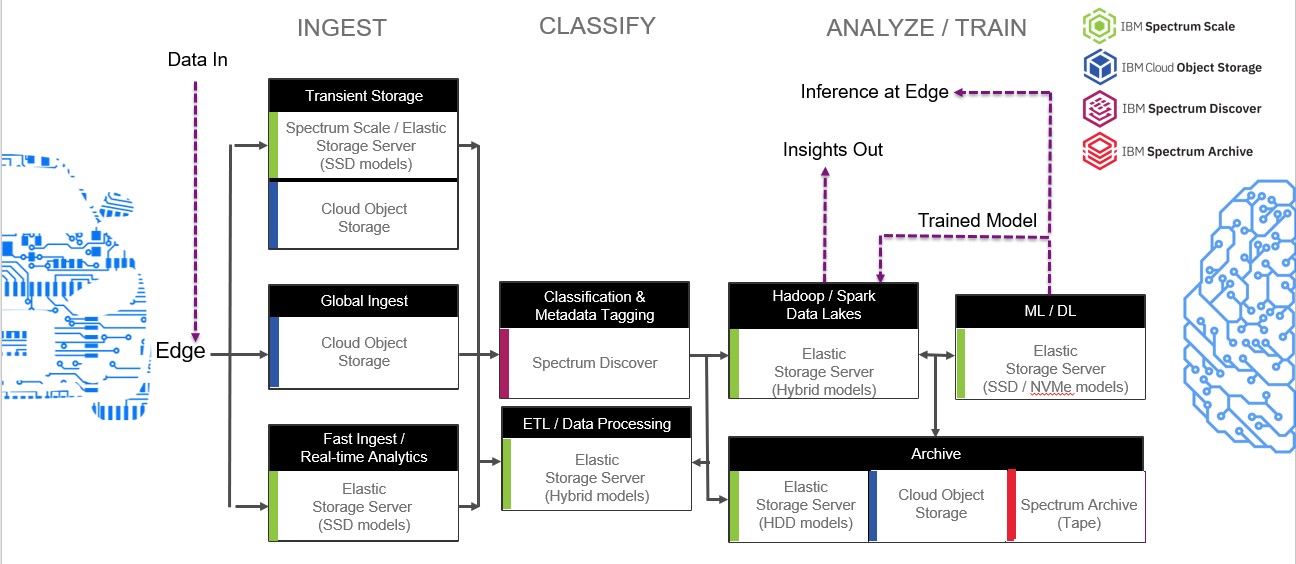
Customers who adopt this end-to-end data pipeline view, while choosing IBM Storage Solutions, can benefit from a data infrastructure that can scale independently for capacity at each stage in the pipeline. There are a number of experienced benefits for teams while doing this, including improved data governance for compliance teams, faster time-to-insight, with minimum number of data copies for data science teams, and simplified management, scalability and improved TCO for infrastructure teams.
Use this meta-framework to your advantage, and stay ahead of this ever-changing AI landscape. Start building your end-to-end data pipeline by downloading the IBM Storage solutions brief
In part three of our series, we’ll explore what it will take to make autonomous driving a reality. The IBM series on insideHPC also covered how the industry can manage and utilize all the data used in AI development for autonomous driving and cars.

