

Wayne Joubert is a Computational Scientist at ORNL.
In this video from the HPC User Forum, Wayne Joubert from Oak Ridge National Laboratory presents: The CoMet Comparative Genomics Application.
Wayne Joubert’s talk described how researchers at the US Department of Energy’s Oak Ridge National Laboratory (ORNL) achieved a record throughput of 1.88 ExaOps on the CoMet algorithm. As the first science application to run at the exascale level, CoMet achieved this remarkable speed analyzing genomic data on the recently launched Summit supercomputer.
Although officially designated as a “Pre-Exascale” system, Summit is the first supercomputer capable of ExaOps. ORNL was able to achieve an unprecedented 2.36 ExaOps level of performance by using mixed-precision on the system’s 27,648 NVIDIA V100 GPUs. Wayne stated that deep learning algorithms can perform effectively with lower precision arithmetic and give comparable results at higher computation rates. In fact, NVIDIA Tensor Core half precision matrix multiplies are 16X faster than double precision counterparts.
ORNL is using Summit to solve comparative genomics problems and seeking genetic causes of individual traits such as susceptibility to disease. To accomplish that, they look at combinations of these traits to see whether they’re occurring and associated with the manifestation of a trait. This is difficult to solve computationally, and the methods they currently use are vector similarity searchs to find the clusters of vectors, where each vector associated with a specific genetic feature.
Vector similarity search is similar to a known problem that they’ve looked at in the HPC community for decades, and it has the same computational pattern as the dense matrix multiply operation, “GEMM” general dense matrix-matrix product. GEMMs can already be computed efficiently by existing high performance software libraries (e.g., NVIDIA CUBLAS, Intel MKL). These libraries schedule the GEMM computations to make best use of the memory hierarchy (registers, caches) on the processor and can thus be adapted to perform the required vector similarity calculations.
Vector Similarity methods include:
- Proportional Similarity (PS) Metric: –much like a GEMM but replaces the floating point multiply with a “minimum of scalars” operation – this “minimum of scalars” is implemented in hardware on many modern processors
- Custom Correlation Coefficient (CCC): – this method operates on binary allele data – it counts the occurrences of joint relationships between genetic features – its computation can exploit the “population count” hardware instruction available in many modern processors.
The NVIDIA V100 GPUs feature Tensor Cores for deep learning applications. A new Tensor Core method uses a mathematical “trick” to convert CCC calculation into a standard GEMM matrix multiply to count the values. This can be done in half precision with no loss of accuracy, enabling a huge speedup using vectors on the Tensor Cores.
These methods apply to multi-GPU systems like Summit with tens of thousands of GPUs. To parallelize the methods, ORNL decomposed the matrices by rows and columns. The resulting matrix blocks were then distributed to the many GPUs to compute the results. The enormous amount of data transfer was done asynchronously to avoid interfering with the computations.
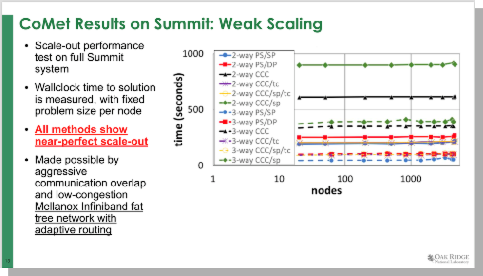
This slide presents a scale-out study on Summit for the whole system in terms of wall clock time. Here the Y axis is the time in seconds, keeping a fixed amount of work per GPU. This was a weak scaling study using basically all the methods provided near-perfect weak scale out to approximately 99% of Summit. This was made possible by the extremely high bandwidth fat tree network with adaptive routing, which enabled nearly congestion-free communications.
Test results showed that Summit’s tensor cores were able to achieve approximately 75% of the peak (mixed precision performance) of Summit. And in fact, this number is slightly greater fraction of peak then is achieved by the HPL benchmark for the TOP500 number, achieved six Teraflops per GPU. This is the advantage they’re getting from the tensor cores
Conclusions and Issue Going Forward:
- Reduced precision offers a great performance boost – are there many more applications can use them?
- Lower precisions are coming — NVIDIA Turing architecture supports INT8, INT4 and INT1 in the Tensor Cores – what applications can take advantage of these devices?
- NVIDIA Tensor Cores only support matrix products – are there other operations that would be useful to run in special purpose compute units?
- “Compute jungle” of increasingly heterogeneous processors as CMOS scaling slows – this is challenging to our developers: code performance portability and maintainability
- Increasing gap between rapidly-growing flop rates between processor generations and slower-growing memory and interconnect bandwidths. This change in system balance is stressing our algorithms – can our codes continue to adapt?
- ORNL has found a way to map a data analytics application to GPUs and exploit fast low-precision hardware on Summit’s Volta GPUs
- Using the Tensor Cores for mixed precision gave ORNL about 4X additional performance over the previous implementation on Summit. This enables a huge advance over state of the art and will allow us to solve previously unsolvable problems
- This work highlights the need to optimize algorithms to current and future architectures to achieve high computational intensity
- Also highlights the growing need to make use of the new kinds of hardware we’re increasingly seeing. “Whatever it takes”
- ORNL is investigating further opportunities to exploit unconventional hardware features on current and future systems

