In this special guest feature from the SC19 Blog, Ryan Quick from Providentia Worldwide calls for a conference program that reflects more sharing across disciplines.
Gray Area Between Computing Paradigms
One of the things that I spend a lot of time thinking about is the gray area between computing paradigms — especially with the rise of what I like to call “generally specialized computing”. Whether you spend your time on campus networks, in the cloud, mining cryptocurrencies, enabling smart cities, or coaxing your algorithms into learning to drive autonomously, the need for powerful and complex computing is omnipresent. Just as the “open office” plan aims to foster unexpected collaboration between workers, the modern compute platform is a hybrid mix of acceleration, high bandwidth, and parallel and distributed tasks. Hybrid computing is here to stay. What hasn’t changed, however, is the terminology experts use to describe their work, and often to segment themselves and others. High performance computing has always been a niche where creativity in engineering flourishes, and it’s high time we widen our vocabulary to become more inclusive of all its aspects.
The “Humpty Dumpty” Dilemma
 I moved into high performance shared-memory computing from hyperscale distributed computing to solve (what I thought would be) a simple problem. I needed to fit more data in memory so that I could simultaneously persist, query, and modify that data as fast as the new stuff was coming in. The hyperscale world became very good at performing atomic transactions in parallel to effect tremendous throughputs. Indeed, their design patterns for doing so became a key definition of “hyperscale” itself. To make these atomic speedups, we spent a lot of time breaking Humpty Dumpty into pieces (now we call this sharding) and ensuring that we could use all of those pieces in client applications concurrently. This was great for atomicity and resiliency. But trying to understand the sum of the parts meant that we needed to put Humpty Dumpty back together again. And we faced a choice: either work to re-assemble the pieces at a rate that can keep up with the influx of new and changed data or query a re-assembled dataset. We could not do both. At least not with the hardware paradigms we had been working on until then. I left that paradigm to explore options in vertical, parallel, and memory coherent computing to help solve that dilemma.
I moved into high performance shared-memory computing from hyperscale distributed computing to solve (what I thought would be) a simple problem. I needed to fit more data in memory so that I could simultaneously persist, query, and modify that data as fast as the new stuff was coming in. The hyperscale world became very good at performing atomic transactions in parallel to effect tremendous throughputs. Indeed, their design patterns for doing so became a key definition of “hyperscale” itself. To make these atomic speedups, we spent a lot of time breaking Humpty Dumpty into pieces (now we call this sharding) and ensuring that we could use all of those pieces in client applications concurrently. This was great for atomicity and resiliency. But trying to understand the sum of the parts meant that we needed to put Humpty Dumpty back together again. And we faced a choice: either work to re-assemble the pieces at a rate that can keep up with the influx of new and changed data or query a re-assembled dataset. We could not do both. At least not with the hardware paradigms we had been working on until then. I left that paradigm to explore options in vertical, parallel, and memory coherent computing to help solve that dilemma.
Unique Jargons and Lexicons Impede Progress
A lot of time has passed since then, and I’ve spent a lot of it learning about how the different paradigms of computing work. When I first embarked on that journey, it surprised me how much resistance I met from engineers, architects, system providers, and systems management organizations as I brought these technologies to bear on novel problems. Over time, the philosopher in me has thought long and hard about how technology creates borders and boundaries as much as it breaks them down. And how we as technologists enforce rules on technology — as if the technology itself somehow resists being applied in new ways. I’ve thought much about these “computation areas”— how they differ from each other and how they are similar; how their supporting communities develop jargons and lexicons unique to their problem spaces, and unfortunately how those jargons keep wider communities from forming.
Complex Problems Require a Unified Approach
Supercomputing to me is just what it sounds like: bringing computing power to solve super problems. High performance computing is the same — leverage extreme hardware and software capabilities (and when you’re lucky both in concert) to bear on some of the toughest problems we face. For my work, it makes no difference whether I am looking to understand a million 4K video streams, a million 4MB log entries, calculating the weather probabilities over a million 1km mesh locations, determining the right cancer cocktail from a list of a million indications for this patient, or determining whether this is the right time to turn on a blinker for that right turn in 100 meters. All of these problems require a complement of hardware and software optimized for a very specific set of problems which must be completed in a very specific time frame. This is what high performance is all about: when the constraints of the problem require extreme predictability and all of the parts of the solution to function correctly in concert at optimum levels. I think of it as Formula One with keyboards.
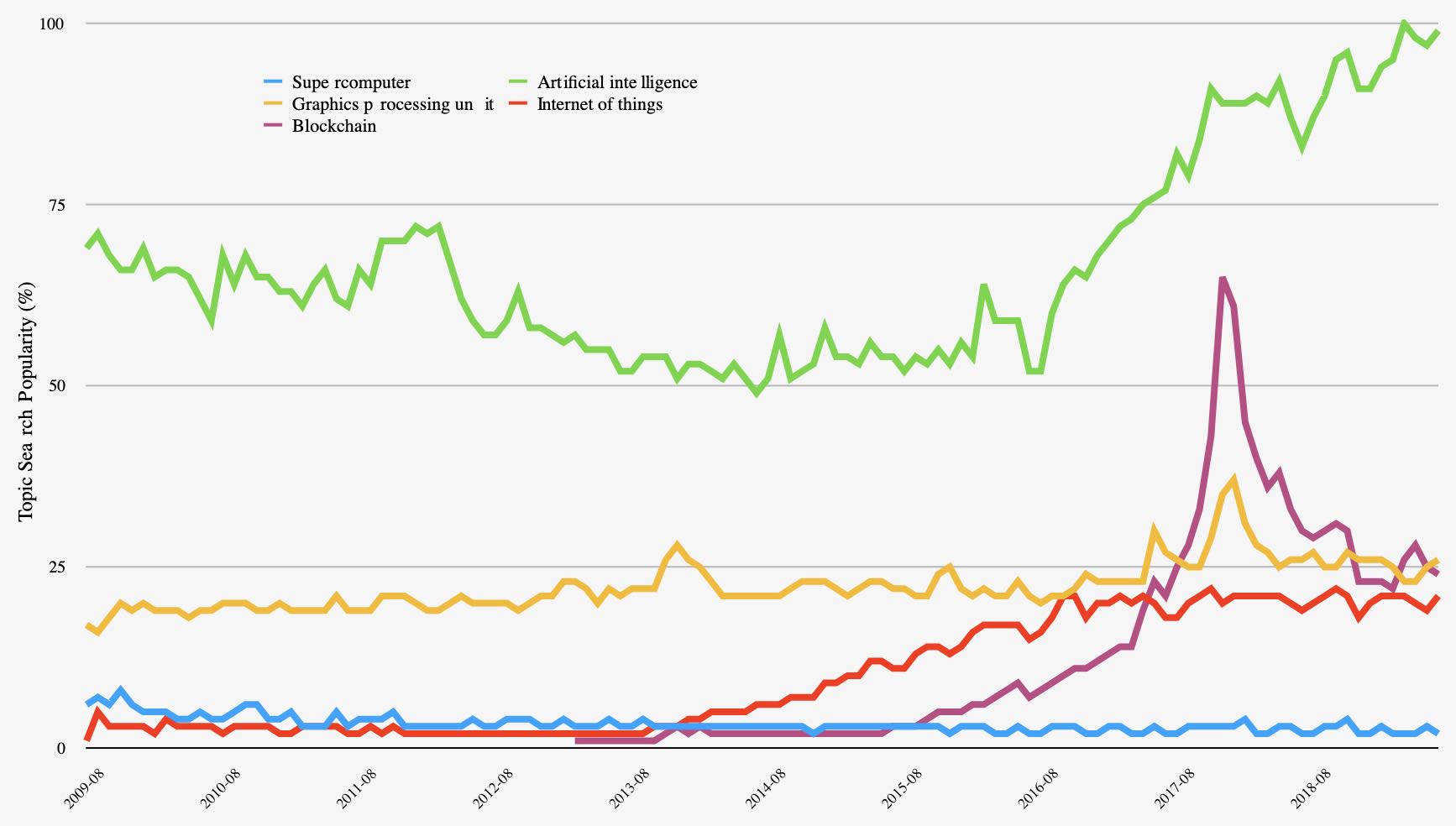
Figure 1: HPC Computing Topics (Data source: Google Trends (https://www.google.com/trends)
We’re All In This Together
The trends in complex computing paradigms are clear. Figure 1 shows niche computing topics over the last decade. These tropics share commonalities in systems design, parallel implementation, and hardware requirements — especially for processing, acceleration, memory, and interconnects. IOT and Blockchain arose in the last five years alone to claim their place in the hallowed halls of high performance. Supercomputing has grown in popularity as the market for compute, accelerators, and interconnects have exploded at the same time. While AI and GPUs have long been topics of conversation, their uses in wider problem spaces bloom during the same window. Taking Figure 1 in aggregate though, we see a marked upswing in the amount of high performance work in the last decade. This trend will continue.
What hasn’t changed is that we see these niches as independent, despite requiring very similar designs and implementations. We’re all in this together and we can quickly gain new heights of computing excellence if we exchange some jargon, recognize that others outside our day-to-day are working on problems which have similar — or even harder — constraints and that by coming together as a larger community we will ourselves perform much better.
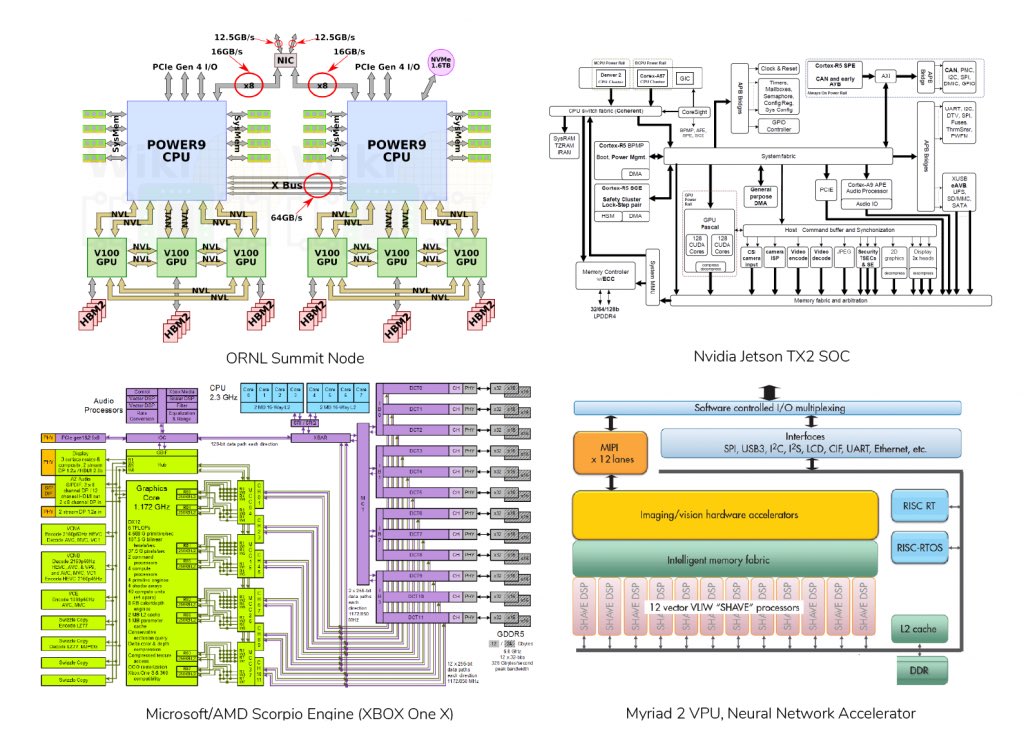
Figure 2: HPC Systems Designs
Towards an Inclusive and Integrated Approach
This year, my hopes for SC19 are that we see more sharing across disciplines. More mixed communities in the BoFs, more common best practices for what these amazing machines can do for us. Figure 2 shows some of my favorite systems. If you can’t tell already, I’m agnostic as to where my computational resources originate as long as I can make the tool work for me. I will beg, borrow, and steal from any paradigm or niche I can to deliver the performance in as an efficient model as possible. For a moment, just allow your eyes to draw back from the specifics in these diagrams and see how alike they are. A node in Summit, currently ranked as the most powerful computing platform on earth, conceptually shares the same components as the USB3-based Neural Compute Stick. The index card sized Jetson TX2 hosts the same Pascal GPU cores as some of our most powerful petascale systems. And for only about $350, the Microsoft Xbox One X packs an enormous computational punch with a truly innovative engine for delivering parallel compute and real-time rendering in 4K HDR. Just imagine with me what it could do for computer vision and network solvers.
For me, HPC is about delivering answers to hard questions – right now. It’s about an inclusive and integrative approach to computing. And it’s exciting. If we can put aside our differences and allow ourselves to learn a little. We will gain a lot. I promise. See you in Denver.
 Ryan Quick is Principal and Co-Founder of Providentia Worldwide, LLC. He received degrees in English and Philosophy from Vanderbilt University. He has been active in the Internet and Linux communities since the early 1990s. He focused on distributed systems for the last 25 years, with special attention to the interaction between applications, operating systems, and the hardware and networks underlying them. Ryan holds patents for messaging middleware systems, and pioneers bridging High-Performance Computing technologies with enterprise best-practices. His HPC work at eBay and PayPal for real-time analytics garnered provisional patents and awards. He is recognized for innovation in hardware and application design, messaging ontology, and event-driven systems. Currently, he brings machine learning, real-time streaming, and blockchain technologies to predictive analytics and artificial intelligence for self-healing in expert systems.
Ryan Quick is Principal and Co-Founder of Providentia Worldwide, LLC. He received degrees in English and Philosophy from Vanderbilt University. He has been active in the Internet and Linux communities since the early 1990s. He focused on distributed systems for the last 25 years, with special attention to the interaction between applications, operating systems, and the hardware and networks underlying them. Ryan holds patents for messaging middleware systems, and pioneers bridging High-Performance Computing technologies with enterprise best-practices. His HPC work at eBay and PayPal for real-time analytics garnered provisional patents and awards. He is recognized for innovation in hardware and application design, messaging ontology, and event-driven systems. Currently, he brings machine learning, real-time streaming, and blockchain technologies to predictive analytics and artificial intelligence for self-healing in expert systems.
Registration is now open for SC19, which takes place Nov. 17-22 in Denver.
Check out our insideHPC Events Calendar

