
This sponsored post from Intel, written by Richard Friedman, depicts how to boost performance for hybrid applications with multiple endpoints in the Intel MPI Library.
The performance of distributed memory MPI applications on the latest highly parallel multi-core processors often turns out to be lower than expected. This is because message passing on shared-memory systems tends to require more synchronization, and thus more overhead, than is necessary.
Which is why hybrid applications using OpenMP multithreading on each node and MPI across nodes in a cluster are becoming more common.
Still, there are further performance gains to be had. An article in a recent Intel Parallel Universe Magazine describes how an enhancement to the Intel MPI Library 2019 called multiple endpoints offers improved performance with hybrid MPI/OpenMP applications.
Multi-EPs extend the MPI_THREAD_MULTIPLE support level to allow multiple threads to be simultaneously active without needing extra synchronization. Now a single MPI rank can use multiple threads to attain higher levels of parallelism without having to create multiple ranks per node.
As the use of hybrid architectures become commonplace, new MPI features such as Multi-EP are needed to achieve the expected high performance at scale.
The article describes an MPI endpoint as a set of resources that support the independent execution of MPI communications. An endpoint corresponds to a rank in an MPI communicator, and, in a hybrid setting, multiple threads can be attached to an endpoint. They communicate using the corresponding endpoint’s resources, which generate multiple streams of data transmitted in parallel. The result is lockless data transmission from the application layer to the threads and the MPI, fabric, and hardware layers.
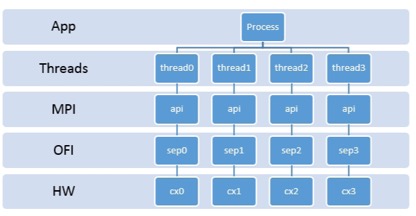
Lockless transmission of messages from the application to the interconnect hardware. (Image: Courtesy of Intel)
The article goes on to show how a thread-compliant MPI code can be set up using environment variables in the Intel MPI Library and the OpenMP runtime. Because the implementation of Multi-EPs is based on the MPI_THREAD_SPLIT(thread-split) programming model, there are some extra requirements that the application code must meet. These restrictions are described in the online documentation.
In two examples, the article compares performance of the pure MPI configuration against a hybrid approach using OpenMP and various numbers of nodes, MPI ranks per node and threads per rank. Using Intel Trace Analyzer and Collector to profile this application and verify the rank and thread decomposition, it was possible to find an optimal thread count for the system under test.
This article is worth studying to see how the Multi-EP optimizations in Intel MPI Library 2019 can result in better performance for hybrid MPI/OpenMP applications on clusters of multi-core processors. Even though a few code changes and environment settings will be required to use this new feature, the changes are minimal and do not impact the overall program structure. As the use of hybrid architectures become commonplace, new MPI features such as Multi-EP are needed to achieve the expected high performance at scale.
Intel MPI Library is a multifabric message-passing library that implements the open-source MPICH specification. Use the library to create, maintain and test advanced, complex applications that perform better on HPC clusters based on Intel processors.
Download the Intel MPI Library.

