(Photo: Shutterstock/ktsdesign)
Artificial Intelligence (AI) and High-Performance Computing (HPC) have become popular sectors of the tech industry, the use case can be seen in a wide range of scenarios such as Next-Generation Sequencing (NGS), molecular dynamics, etc. In order to fulfill such workloads, an elegant and robust IT infrastructure is required. Accelerated computing have been viewed as revolutionary breakthrough technologies for AI and HPC workloads. Significant accelerated computing power from GPUs paired with CPUs is the major contributor.
Our friends over at Quanta Cloud Technology (QCT) provide QuantaGrid D52G-4U 8 NVLink GPUs servers with a liquid cooling platform successfully adopted by the National Center of High-performance Computing (NCHC) in Taiwan) for their Taiwania-II project. Rank 23rd on the Top500 as of June 2019.
Use Case: NCHC TAIWANIA 2
Quanta Cloud Technology (QCT), a global data center solution provider, in collaboration with ‘National Center for High-performance Computing’ (NCHC), who provides high performance computing resource to Research Institutes and other HPC users in Taiwan, built the Taiwania-II – a Peta Scale AI/HPC system.
The GPU server plays an important role in the NCHC project,
- The GPU cluster that QCT built consists of 252x QuantaGrid D52G-4U servers
- Each with 8 NVIDIA Tesla V100 SXM2 32GB GPUs
- The QuantaGrid D52G-4U adopted in this case can achieve up to 56 double precision (FP64) TFLOPS of computing power
- There are a total of 2,016 GPUs in the system to achieve 9 PFLOPS on the HPL benchmark
Energy saving is always a key consideration in Peta Scale projects in order to reduce total operation cost during the life cycle of the system. In order to deliver an energy efficient system, Direct Liquid Cooling(DLC) technology has been designed into the 8Way GPU server. With this optimized design on DLC technology with integrated facility cooling equipment, the Taiwania-II achieves a PUE at 1.16 and has been ranked at No.9 on the Green500 as of June 2019. As to assure the delivery serviceability, quality, and to reduce the racking at the customer site, QCT provided the system in a rack-level integration, which means all the servers,Cooling Distribution Unit (CDU), and Cooling Distribution Modules (CDM) were integrated before delivery. The system would of course be pre-configured and pre-validated to provide the best practice in power and network cabling. This eliminated lots on site hardware diagnosis efforts and reduced cumbersome on-site racking labor efforts.
All-in-one Box prevails over AI and HPC challenge
QuantaGrid D52G-4U is a purpose-built system for GPU-accelerated Artificial Intelligent (AI) and High-Performance Computing (HPC) workloads. The QuantaGrid D52G-4U can:
- Deliver up to 56 double precision TFlops and 2x100Gb/s high bandwidth low latency networking with 8 [1] NVIDIA® Tesla® V100 Support up to 300GB/s GPU to GPU communication with NVLink™
- Support up to 10x dual-width 300Watt GPU or 16x single-width 75Watt GPU in one chassis.
- Provide multiple GPU topologies to conquer any type of parallel computing
- Support for up to 4x100Gb/s high bandwidth RDMA-enabled network to scale out with efficiency
- Support 8x NVMe storage to accelerate deep learning
GROMACS Workload Optimization
Optimize CPU & GPU combination
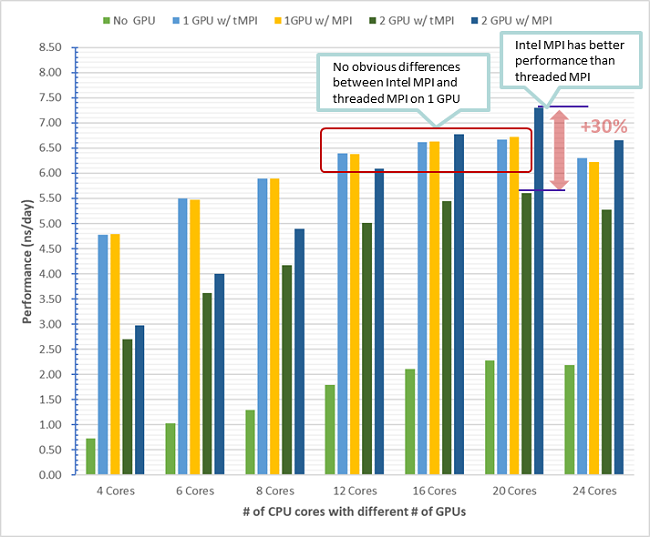
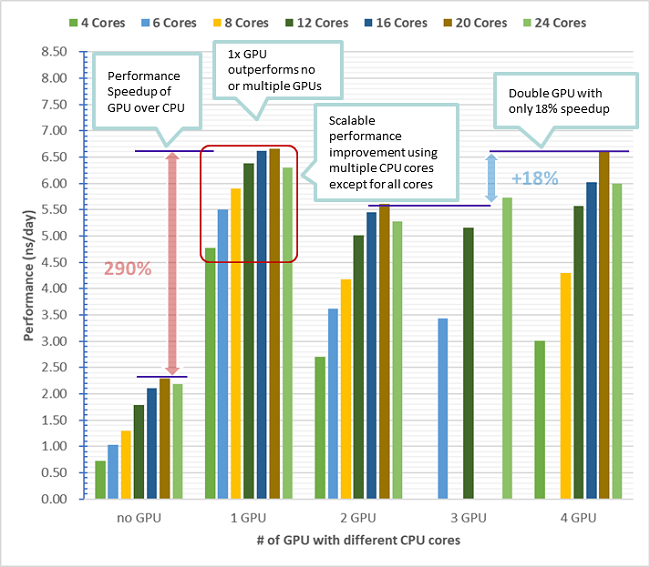
The features above make the QuantaGrid D52G-4U ideal for GPU-accelerated AI or HPC workloads such as bioinformatics, which also apply GROMACS when processing bioinformatic workloads. GROMACS is one of the freely available, popular, and widely-used molecular dynamics (MD) engines. In order to enhance the performance of GROMACS, we have conducted a comprehensive test on the QuantaGrid D52G-4U to demonstrate the performance difference by optimizing the combinations of CPUs and GPUs within a single node. The bullet points listed below elaborate the conclusions for the test result:
- Better performance using Intel MPI than using default threaded MPI in GROMACS 2018.7 on single GPU node
- Better performance on single node with one GPU than no GPU neither multiple GPUs
- Better performance by using as many CPU cores as possible on single GPU node, but reserved several CPU cores for OS
- GPU significantly accelerates computing but more GPUs will diminish cost-effectively benefits on single GPU node
[1] Max. NVIDIA® dual-width GPU qty is eight due to vendor software limitation. D52G-4U still can install 10x dual-width AMD® GPU, but there is only PCIe expansion slot available on motherboard while installing 10x dual width GPU.