The new no. 1 system on the updated ranking of the TOP500 list of the world’s most powerful supercomputers, released this morning, is Fugaku, a machine built at the Riken Center for Computational Science in Kobe, Japan. The system turned in a High Performance LINPACK (HPL) result of 415.5 petaflops (nearly half an exascale), outperforming Summit, the former no. 1 system housed at the U.S. Dept. of Energy’s Oak Ridge National Lab, by a factor of 2.8x.

Fugaku supercomputer at Riken
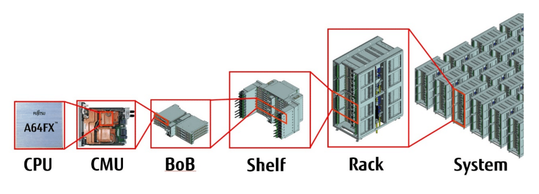
Fugaku, powered by Fujitsu’s 48-core A64FX SoC, is the first ARM-based system to take the TOP500 top spot. The system, which has 158,976 nodes, blew through the exascale (a billion billion calculations per second) milestone in single precision calculations, often used in machine learning and AI applications. On the HPL-AI benchmark, designed to measure HPC performance on machine/deep learning workloads, Fugaku registered peak performance of 1.45 exaflops, according to Jack Dongarra, Distinguished Professor of Computer Science at the University of Tennessee, who helped create the TOP500 list in 1993.
“This is an impressive machine,” Dongarra told us. “It has great potential. They’ve run a number of applications already on the Fugaku system, and I expect to see many good things come out of it. It’s a very well balanced machine. It was designed to do supercomputing – that is to say, it wasn’t cobbled together from commodity processors and GPUs. It was designed specifically for this high end, high performance computing.”
Number two on the TOP500 list is Summit, an IBM-built supercomputer that delivers 148.8 petaflops on the LINPACK benchmark. The system, which has 4,356 nodes, each with two 22-core Power9 CPUs and six NVIDIA Tesla V100 GPUs, remains the fastest supercomputer in the US. At number three is Sierra, at the Lawrence Livermore National Laboratory, achieving 94.6 petaflops on HPL. Also built by IBM and with an architecture similar to Summit, it’s equipped with two Power9 CPUs and four NVIDIA Tesla V100 GPUs in each of its 4,320 nodes.
Sunway TaihuLight, developed by China’s National Research Center of Parallel Computer Engineering & Technology (NRCPC) drops to number four on the list. The system is powered entirely by Sunway 260-core SW26010 processors and its HPL mark of 93 petaflops has remained unchanged since it was installed at the National Supercomputing Center in Wuxi, China in June 2016, according to the TOP500.
Fugaku, powered by Fujitsu’s 48-core A64FX SoC, is the first ARM-based system to take the TOP500 top spot. The system, which has 158,976 nodes, blew through the exascale (a billion billion calculations per second) milestone in single precision calculations, often used in machine learning and AI applications. On the HPL-AI benchmark, designed to measure HPC performance on machine/deep learning workloads, Fugaku registered peak performance of 1.45 exaflops….
At number five is Tianhe-2A (Milky Way-2A), developed by China’s National University of Defense Technology with HPL performance of 61.4 petaflops. It has a hybrid architecture employing Intel Xeon CPUs and custom-built Matrix-2000 coprocessors and is deployed at the National Supercomputer Center in Guangzhou, China.
A new system on the list, HPC5, a PowerEdge system built by Dell and installed by the Italian energy firm Eni S.p.A, captured the number six spot with an HPL performance of 35.5 petaflops. HPC5 is the fastest supercomputer in Europe and the world’s most powerful system for commercial use. It is powered by Intel Xeon Gold processors and NVIDIA Tesla V100 GPUs and uses Mellanox HDR InfiniBand as the system network.
Fugaku system configuration (source: Jack Dongarra)
Another new system, Selene, is at number seven with an HPL mark of 27.58 petaflops. It is an Nvidia DGX SuperPOD, powered by Nvidia’s new “Ampere” A100 GPUs and AMD’s EPYC “Rome” CPUs. Selene is installed at NVIDIA in the US and uses Mellanox HDR InfiniBand as the system network.
Frontera, a Dell C6420 system installed at the Texas Advanced Computing Center (TACC) in the US is ranked eighth on the list. Its 23.5 HPL petaflops is achieved with 448,448 Intel Xeon cores. Marconi-100, at 21.6 petaflops and installed at Italy’s CINECA research center comes in no. 9. It is powered by IBM Power9 processors and NVIDIA V100 GPUs, employing dual-rail Mellanox EDR InfiniBand. Rounding out the top 10 is Piz Daint at 19.6 petaflops, a Cray XC50 system installed at the Swiss National Supercomputing Centre in Lugano, Switzerland. It is equipped with Intel Xeon processors and NVIDIA P100 GPUs.
A complete listing of the updated TOP500 will be released by the organization here.
Impressed as he is by Fugaku, Dongarra cautioned that the new no. 1 system is not an exascale supercomputer.
“No, I would not pose it as the first exascale machine,” he said. “The Summit machine had a peak performance over an exaflop – I think the peak for Summit was about three exaflops, but it couldn’t achieve that on the (LINPACK) benchmark. And for most scientific applications, we talk about 64-bit computation. So for 64-bit, we’re still under an exaflop.”
Taking the list in aggregate, the TOP500 totals 2.23 exaflops, up from 1.65 exaflops six months ago. The majority of that increase is the result of the new number one Fugaku supercomputer. The new entry point on the list (system number 500) is 1.24 petaflops, only a slight increase from the previous list. Overall the number of new systems in the list is only 51, a record low since the beginning of the TOP500 in 1993.
TOP500 said China dominates the list with 226 supercomputers. The U.S. is number two with 114; Japan third with 30; France has 18; and Germany claims 16. Despite coming in second on system count, the US continues to edge out China in aggregate list performance with 644 petaflops to China’s 565 petaflops. Japan, with its significantly smaller system count, delivers 530 petaflops, TOP500 reported.
The organization said 144 systems on the list use accelerators (135 use Nvidia GPUs) or coprocessors, one less than six months ago. As has been the case in the past, the majority of the systems equipped with accelerator/coprocessors (135) are using NVIDIA GPUs.
Having said that, the x86 continues to be the dominant processor architecture, it’s used in 481 of the 500 systems. Intel claims 469 of these, with AMD installed in 11 and Hygon in the remaining one. Arm processors are present in just four TOP500 systems, three of which employ the new Fujitsu A64FX processor, with the remaining one powered by Marvell’s ThunderX2 processor, according to TOP500.


An important detail to pull out is that the HPCG performance of the Post-K machine is 5x that of Summit at a little north of 14 petaflops and twice Summits efficiency. That 5x multiplier is arguably the most relevant metric for the 64-bit boffin. The Japanese have shown tremendous leadership again and strategic focus while others struggle to incorporate stacked HBM memory designs into something that’s straight forward to program. Hopefully we can begin to see other HBM based designs that can better facilitate portability.