

Source: Randall Munroe, xkcd (Creative Commons license)
Physics-based simulations, that staple of traditional HPC, may be evolving toward an emerging, AI-based technique that could radically accelerate simulation runs while cutting costs. Called “surrogate machine learning models,” the topic was a focal point in a keynote on Tuesday at the International Conference on Parallel Processing by Argonne National Lab’s Rick Stevens.
Stevens, ANL’s associate laboratory director for computing, environment and life sciences, said early work in “surrogates,” as the technique is called, shows tens of thousands of times (and more) speed-ups and could “potentially replace simulations.”
Surrogates can be looked at as an end-around to two big problems associated with traditional HPC simulation:
- Time consuming; when running, other research work tends to stop while scientists wait for results (Stevens cited the above Randall Munroe cartoon).
- Speeding up traditional sims is expensive, calling for more compute muscle and enhanced software.
In his keynote, entitled, “Exascale and Then What?: The Next Decade for HPC and AI,” Stevens explained surrogates this way:
“You have a system, it could be a molecular system or drug design…, and you have a physics-based simulation of it… You run this code and capture the input-output relationships of the core simulation… You use that training data to build an approximate model. These are typically done with neural networks… and this surrogate model approximates the simulation, and typically it is much faster. Of course, it has some errors, so then you use that surrogate model to search the space, or to advance time steps. And then maybe you do a correction step later.”

Rick Stevens, Argonne
Why, specifically, do surrogates run faster?
“The fundamental reason for the speedup,” Stevens told us in an email, “is that doing inferencing in deep neural networks (or other ML methods) is in general significantly faster (i.e. less floating point operations) than solving the original simulation problem. Deep neural networks in inferencing mode also can utilize lower precision (i.e. fp32 or bfp16) which also provides a performance advantage over fp64 and can take advantage of matrix oriented hardware accelerators in a very efficient fashion. The surrogate is generally solving an approximation of the original problem, but even with the additional work to address any errors they are many orders of magnitude faster.”
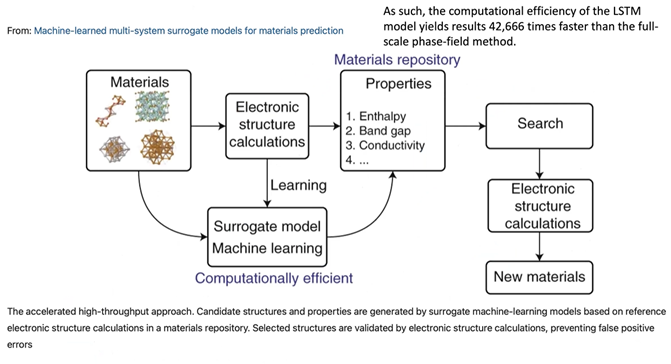
Put another way, the authors of a paper published in NPJ / Computational Materials described surrogates this way:
“The key idea is to use machine learning to rapidly and accurately interpolate between reference simulations, effectively mapping the problem of numerically solving for the electronic structure of a material onto a statistical regression problem. Such fast surrogate models could be used to filter the most suitable materials from a large pool of possible materials and then validate the found subset by electronic structure calculations. Such an ‘accelerated high-throughput’ approach could potentially increase the number of investigated materials by several orders of magnitude.”

source: https://arxiv.org/abs/2001.08055
Another encouraging aspect of surrogates is that the technique is applicable across multiple disciplines. Stevens cited two research papers, from 2019 and another from early last year in which the former took on the classic Newtonian problem of calculating three objects orbiting each other; the latter, cites promising results in the fields of astrophysics, climate science, biogeochemistry, high energy density physics, fusion energy, and seismology.
So this concept seems to not only work, but it works with some generality,” Stevens said.
Stevens and his team at Argonne applied the technique to drug design simulations and realized gains of about 42,000 times faster than the underlying simulation, he said. Looking ahead to next-gen supercomputing, Stevens said running surrogates on Argonne’s upcoming Aurora exascale-class system “I’m effectively running at 1000 or 10,000, or perhaps 100,000 times faster… I’m solving essentially the same problem with ML and I’m now effectively running at a zeta-scale, or perhaps higher than that. So we think this is an important thing.”
As for adoption by the HPC community, Stevens said, “I believe that most cutting edge groups will be doing some form of hybrid AI/simulation version of their codes in the next three to five years. The performance gains are going to be hard to ignore as well as the ability to utilize additional datasets to improve the models, something that is very difficult to do without some form of machine learning. Like most new things some groups will be out in front while others will lag behind. What is interesting is how broad the potential utilization of these methods are, ranging from problems in drug docking, to quantum chemistry to climate. Pretty much any PDE or ODE system has some opportunity.”


i see 28 abstracts on surrogate models at the NAFEMS World Congress 2021, plus some great progress reported at ISC 2021 https://hpcsquaire.org/2021/07/13/surrogate-models-integrating-an-hpc-solver-and-a-machine-learning-component/
These surrogate models sound very interesting, but also very similar to a direction of research that I have started in 2017 and which can be found below :
https://arxiv.org/abs/1710.10940
https://arxiv.org/abs/1806.00082
https://arxiv.org/abs/1807.06939
In particular, what I have been doing was to train neural networks to compute a particular physical quantity (the Wigner kernel) to achieve very fast simulations of quantum systems.
I am wondering if Prof. Stevens is aware of this. If not, it would be interesting to make a connection I guess 🙂