
ALCF researchers Huihou Zheng (left) and Venkat Vishwanath were part of the DLIO benchmark suite development team
The emergence of deep learning techniques has provided a new tool for accelerating scientific exploration and discoveries. A group of researchers from the Argonne Leadership Computing Facility (ALCF) and the Illinois Institute of Technology (IIT) set out to improve the efficiency of deep learning-driven research by developing a new benchmark, named DLIO, to investigate the data input/output (I/O) patterns of various deep learning applications. The ALCF is a U.S Department of Energy (DOE) Office of Science User Facility at Argonne National Laboratory.
Using DLIO, the researchers are able to identify data bottlenecks that hinder I/O performance in deep learning applications, providing an avenue for researchers to extract more performance from supercomputers. The team, which included ALCF computer scientists Huihuo Zheng and Venkatram Vishwanath and IIT researchers Hariharan Devarajan, Anthony Kougkas, and Xian-He Sun, was recently awarded best paper for their work with DLIO at the Institute of Electrical and Electronics Engineers (IEEE)/Association for Computing Machinery (ACM) International Symposium on Cluster, Cloud and Internet Computing (CCGrid).
The team’s paper, titled “DLIO: A Data-Centric Benchmark for Scientific Deep Learning Applications,” details the deep learning workloads of eight scientific deep learning applications running on the ALCF’s Theta supercomputer. Devarajan, a PhD student at IIT, began the work in collaboration with Argonne staff as an intern at the ALCF in 2020.
“Deep learning applications involve repeatedly loading large volumes of data from the file system at each training epoch. Input/output (I/O) is a potential bottleneck in large-scale scientific deep learning as the size of dataset grows,” Zheng said. “With the increase in deep learning processing capabilities in current and future processors, the gap between computation and I/O for deep learning is expected to grow even more. The ability to identify these bottlenecks and provide optimization strategies and solutions is of paramount importance for distributed training and inference on upcoming exascale platforms.”
The team evaluated workloads from DOE’s Exascale Computing Project, ALCF’s Aurora Early Science Program, and the ALCF Data Science Program to understand the typical I/O patterns of scientific deep learning applications that use current and future ALCF supercomputers.
As part of their work, they developed a holistic profiler that combines logs from deep learning frameworks, such as Tensorflow, together with I/O and storage systems logs to better understand the application behavior. Next, they built the representative benchmark, DLIO, that allowed them to emulate applications’ data access patterns, identify I/O bottlenecks, and evaluate performance optimizations at scale on Theta.
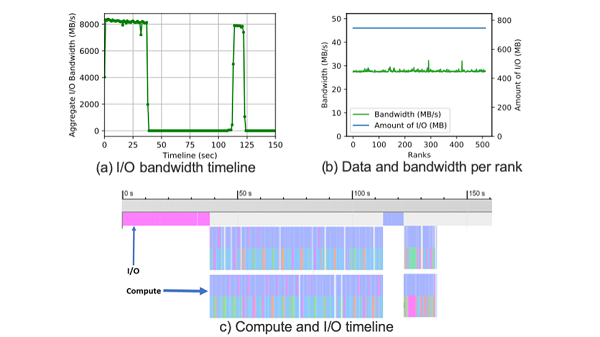
I/O behavior of CANDLE NT3 DL application: a) shows the aggregate bandwidth achieved of 8 GB/s for the applications. b) depicts the distribution of I/O (i.e., 700 MB) and achieved bandwidth (28 MB/s) across ranks. c) shows the merged timeline of I/O and compute, which shows that I/O and compute do not overlap in the application.
They found deep learning applications use scientific data formats that are not well-supported by deep learning frameworks; however, their representative benchmark DLIO, provided the necessary insights and optimizations to improve the efficiency and time to solution by six times on some of the existing applications.
“We were able to identify various strategies for optimizing deep learning workloads such as prefetching of data, overlapping the I/O with computation, efficient data movement, and multi-threaded data loading,” Zheng said. “We are now working toward a deep learning I/O library that enables all these optimizations for scientific data formats. We believe our work will provide a roadmap for efficient data management for AI applications on future exascale supercomputers.”
source: Logan Ludwig, ALCF

