Sponsored Post
Ehsan Totoni, CTO Bodo.ai
“As miniaturization approaches its limits, bringing an end to Moore’s law, performance gains will need to come from software, algorithms, and hardware.”
~ There’s plenty of room at the Top: What will drive computer performance
after Moore’s law? Charles E. Leiserson et al, Science, (5 June 2020)
The Market’s Hunger for Analytics Compute Power
Leaders in Computer Science today tend to agree that Moore’s law is in jeopardy. In fact, for general-purpose CPUs, Moore’s Law hit a wall around 2005. Manufacturers just couldn’t clock CPUs any faster (the laws of physics got in the way). This might not significantly affect average computer users. But for power computer users such as data engineers, data scientists, analytics users, media processing and AI/ML, these limitations posed a very real threat to progress.
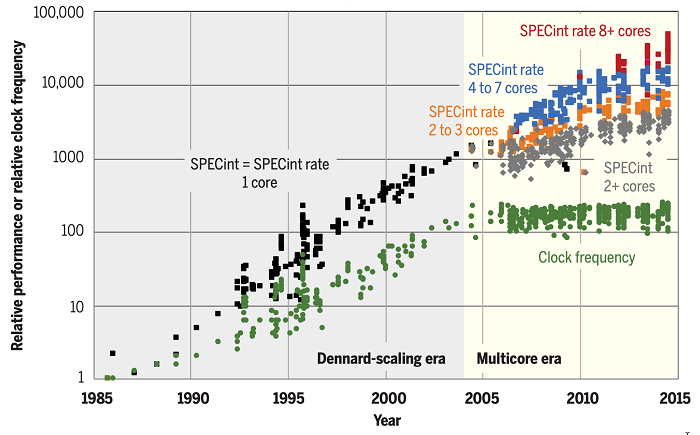
SPECint (largely serial) performance, SPECint-rate (parallel) performance, and clock-frequency scaling for microprocessors from 1985 to 2015, normalized to the Intel 80386 DX microprocessor in 1985. ~ There’s plenty of room at the Top: What will drive computer performance after Moore’s law? Charles E. Leiserson et al, Science, (5 June 2020)
In response, manufacturers began following two new strategies to extend Moore’s Law into the future:
- Adding more CPU Cores: Chip makers began adding more cores to their general-purpose chips, giving them extra power. Unfortunately, there’s a limit to the number of cores that fit on a wafer, plus software doesn’t always make optimal use of these cores unless it’s carefully crafted. So therefore, this multicore CPU approach is about to hit a wall, too.
- Develop new domain-specific chips: processors that are optimized for special purposes (i.e. RISC, GPUs and others) are much faster than general purpose (i.e. x86) CPUs. So a market has developed for these “Domain-Specific Accelerators” for computing. But again, writing software for this specific hardware must be carefully crafted. Worse, It’s also not portable to other infrastructures. And, no surprise, these processors are also hitting performance walls themselves, requiring crafting of multicore approaches.
 On top of these strategies, the software industry also attempted to solve this performance problem for mainstream programming languages (e.g. Python) and analytics libraries (e.g. Pandas). It includes developing libraries such Spark and Dask, that attack the multi-processing issue from the software side. These approaches – broadly adopted today – help computing performance by distributing processing across multiple CPUs using a technique to schedule parts of computing jobs when needed. This is technically distributed computing, using a “driver/executor” approach (one driver, lots of executors). Not surprising, there are issues with this approach as well:
On top of these strategies, the software industry also attempted to solve this performance problem for mainstream programming languages (e.g. Python) and analytics libraries (e.g. Pandas). It includes developing libraries such Spark and Dask, that attack the multi-processing issue from the software side. These approaches – broadly adopted today – help computing performance by distributing processing across multiple CPUs using a technique to schedule parts of computing jobs when needed. This is technically distributed computing, using a “driver/executor” approach (one driver, lots of executors). Not surprising, there are issues with this approach as well:
- These software techniques are themselves difficult to learn, must be carefully crafted/tuned to take advantage of multiple CPUs
- They don’t scale linearly, suffering from the bottleneck created by the scheduler
- The approaches are themselves often hardware-specific (e.g. using RAPIDs with GPUs)
- They’re hugely resource-inefficient, in that individual CPUs often sit idle during compute jobs, until the scheduler assigns a new action to them
As a result, the Computer Science community uniformly agrees that true parallel computing technologies are the only way forward to maintain growth in compute performance in the future.
Parallel computing – in theory – is far faster and more efficient than distributed computing, because all CPUs (whatever their type) are used 100% of the time, and can be scaled completely linearly because there is no “scheduler” involved. The hitch – up until now – is that programming for true parallel computing has been the domain of rarified experts.
A Path Forward
Given computing’s current challenges, a “holy grail” solution to the Moore’s Law crisis must embody 3 core principles:
- Allow the developer community to continue to use broadly-adopted high-level, general-purpose languages
- Enable CPU parallelization that scales linearly and efficiently, without special-purpose hardware or coding techniques.
- Make optimal use of general-purpose as well as current (and future) domain-specific hardware
I have approached these principles as part of a core architecture vision. The aim has been to engineer a universal, high-performance parallel computing platform, integratable into any data analytics platform, storage solution, work-flow tool, or use-case scenario.
 At the core of the approach is a unique “inferential” compiler that can be used with a high-level language such as Python/Pandas. The compiler assesses the code’s use of language and syntax, looking for opportunities to parallelize into MPI-style LLVM code (the type that “true” parallel software experts use). This avoids scheduler bottlenecks, and guarantees extremely efficient use of CPU cores. Even better, this approach inherently scales linearly, so there is no adjustment/tuning needed to scale from 8 laptop cores to over 10,000 cloud CPUs.
At the core of the approach is a unique “inferential” compiler that can be used with a high-level language such as Python/Pandas. The compiler assesses the code’s use of language and syntax, looking for opportunities to parallelize into MPI-style LLVM code (the type that “true” parallel software experts use). This avoids scheduler bottlenecks, and guarantees extremely efficient use of CPU cores. Even better, this approach inherently scales linearly, so there is no adjustment/tuning needed to scale from 8 laptop cores to over 10,000 cloud CPUs.
Programmers simply write native code (optionally using analytics libraries like Pandas) and invoke a just-in-time compiler. There are no additional libraries or APIs to invoke. And the beauty is that it preserves the ability to continue to use popular programming approaches.
Finally, logic can be included to identify the kind of CPU resource that would best work with the type, format and even size of data (e.g. structured, unstructured, streaming, media, etc.) to optimize the parallel code for that hardware. This feature means this model can “orchestrate” use of domain-specific compute resources to assign the ideal hardware that the data analytics problem requires.
Parallel Compilation Concept in Practice
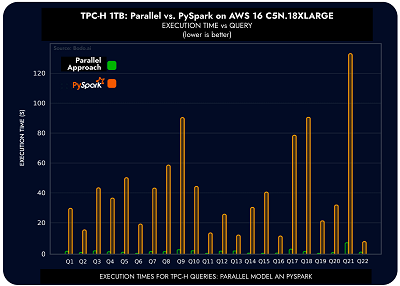 My company (Bodo.ai) chose to evaluate this approach using the TPC-H benchmark since its queries are simpler to convert to Python than others like TPCxBB and TPC-DS, but it still provides representative computations. We used all standard TPC-H benchmarks (22 in all) to compare economic and speed performance vs Spark (perhaps the most popular distributed computing library in use for data processing workloads). On a 1TB dataset, we found that this new parallel approach provided a 22.9x median speedup over Spark with an associated 95%+ compute cost reduction due to compute resource efficiency gains.
My company (Bodo.ai) chose to evaluate this approach using the TPC-H benchmark since its queries are simpler to convert to Python than others like TPCxBB and TPC-DS, but it still provides representative computations. We used all standard TPC-H benchmarks (22 in all) to compare economic and speed performance vs Spark (perhaps the most popular distributed computing library in use for data processing workloads). On a 1TB dataset, we found that this new parallel approach provided a 22.9x median speedup over Spark with an associated 95%+ compute cost reduction due to compute resource efficiency gains.
Looking forward, we see opportunities to integrate this parallelization approach – capable of scaling to 10k cores or more – into popular cloud-based Data Warehouses to help speed large-scale analytics and ELT computing. And, because the model can be engineered for various special-purpose hardware and accelerators, we see opportunities to apply this to GPUs and FPGAs for media processing and encoding as well.
I invite the HPC and analytics community to learn more, and to experiment with this commercially-available approach.
Ehsan Totoni is an entrepreneur, computer science researcher, and software engineer working on democratization of High-Performance Computing (HPC) for data analytics/AI/ML. Ehsan received his PhD in computer science from the University of Illinois at Urbana-Champaign, working on various aspects of HPC and Parallel Computing. He then worked as a research scientist at Intel Labs and Carnegie Mellon University, focusing on programming systems to address the gap between programmer productivity and computing performance. He can be reached at ehsan@bodo.ai

