![]() As HPC enters the exascale era, watchers of the TOP500 list of the world’s most powerful supercomputers will look to see if the updated list, to be released this month at the ISC conference in Hamburg, will include systems that break the vaunted exaflops barrier. That said, Google Cloud yesterday unveiled what it called the world’s largest public machine learning hub. Powered by Cloud TPUs (Tensor Processing Unit) v4, Google said it has a peak aggregate cluster performance of a whopping 9 exaFLOPS.
As HPC enters the exascale era, watchers of the TOP500 list of the world’s most powerful supercomputers will look to see if the updated list, to be released this month at the ISC conference in Hamburg, will include systems that break the vaunted exaflops barrier. That said, Google Cloud yesterday unveiled what it called the world’s largest public machine learning hub. Powered by Cloud TPUs (Tensor Processing Unit) v4, Google said it has a peak aggregate cluster performance of a whopping 9 exaFLOPS.
And it operates at 90 percent carbon-free energy, according to Google.
Google launched version 4 of its TPU last year; a TPU pod consists of 4,096 of these chips, each with a peak performance of 275 teraflops and each pod with a combined power of up to 1.1 exaflops of compute power, according to the company. Google said it operates a full cluster of eight pods in its Oklahoma data center, delivering up to 9 exaflops of peak performance.
Announced yesterday at the Google I/O developer conference, the company said Google Cloud’s ML cluster is “one of the fastest, most efficient, and most sustainable ML infrastructure hubs in the world, enabling researchers and developers to train increasingly sophisticated and complex models to power such workloads as large-scale natural language processing recommendation systems and computer vision algorithms.
Google cited IDC’s Matt Eastwood, SVP, Research in a blog announcing the cluster. “Based on our recent survey of 2000 IT decision makers, we found that inadequate infrastructure capabilities are often the underlying cause of AI projects failing, “ Eastwood said. “To address the growing importance for purpose-built AI infrastructure for enterprises, Google launched its new machine learning cluster in Oklahoma with nine exaflops of aggregated compute. We believe that this is the largest publicly available ML hub with 90% of the operation reported to be powered by carbon free energy. This demonstrates Google’s ongoing commitment to innovating in AI infrastructure with sustainability in mind.”
“In addition to the direct clean energy supply, the data center has a Power Usage Efficiency (PUE)1 rating of 1.10, making it one of the most energy-efficient data centers in the world,” stated Google’s Sachin Gupta, VP/GM, Infrastructure, and Max Sapozhnikov, product manager, Cloud TPU. “Finally, the TPU v4 chip itself is highly energy efficient, with about 3x the peak FLOPs per watt of max power of TPU v3. With energy-efficient ML-specific hardware, in a highly efficient data center, supplied by exceptionally clean power, Cloud TPU v4 provides three key best practices that can help significantly reduce energy use and carbon emissions.”

TPU v4 chip tray; TPU v4 pods at our Oklahoma data center (credit: Google)
They said the ML cluster addresses two needs common in AI model training: scale and price-performance. On scale, Google said the TPU chips in a pod are connected by an ultra-fast interconnect network with “the equivalent of an industry-leading 6 terabits per second (Tbps) of bandwidth” per host.
On price-performance, Google said Cloud TPU v4 chips have ~2.2x more peak FLOPs than Cloud TPU v3, for ~1.4x more peak FLOPs per dollar. And the company said the chip achieves high FLOPS utilization for training ML models at scale up through thousands of chips.
“While many quote peak FLOPs as the basis for comparing systems,” Gupta and Sapozhnikov said, “it is actually sustained FLOPs at scale that determines model training efficiency, and Cloud TPU v4’s high FLOPs utilization (significantly better than other systems due to high network bandwidth and compiler optimizations) helps yield shorter training time and better cost efficiency.”
Google said Cloud TPU v4 Pod slices are available in configurations ranging from four chips (one TPU VM) to thousands of chips. While slices of previous-generation TPUs smaller than a full Pod lacked torus links (“wraparound connections”), all Cloud TPU v4 Pod slices of at least 64 chips have torus links on all three dimensions, providing higher bandwidth for collective communication operations.
Cloud TPU v4 also enables accessing 32 GiB of memory from a single device, up from 16 GiB in TPU v3, and offers two times faster embedding acceleration, helping to improve performance for training large-scale recommendation models.
Access to Cloud TPU v4 Pods comes in evaluation (on-demand), preemptible, and committed use discount (CUD) options.
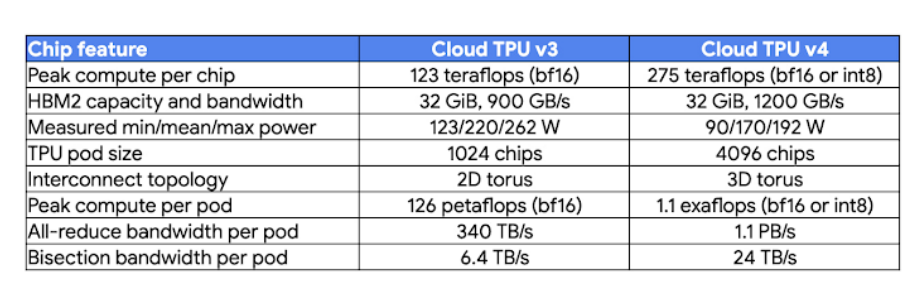
Cloud TPU v4 pods performance table (source: Google)


Comparing bf16 with the 64-bit FLOPS used for the TOP500 is disingenuous at best.