
Today HPC Startup Appentra Solutions announced the company’s plans to showcase its auto-parallelization technologies at the Emerging Technologies Showcase at SC18. “SC18 is the premier international conference for High Performance Computing, networking, storage, and analysis. Every year, the Emerging Technologies program at the SC conference, showcases innovative solutions, from industry, government laboratories and academia, that may significantly improve and extend the world of HPC in the next five to fifteen years.”
Search Results for: parallelization
Appentra Joins OpenPOWER Foundation for Auto-Parallelization
January 22, 2017 by

Today Appentra announced it has joined the OpenPOWER Foundation, an open development community based on the POWER microprocessor architecture. Founded in 2012, Appentra is a technology company providing software tools for guided parallelization in high-performance computing and HPC-like technologies. “The development model of the OpenPOWER Foundation is one that elicits collaboration and represents a new way in exploiting and innovating around processor technology.” says Calista Redmond, Director of OpenPOWER Global Alliances at IBM. “With the Power architecture designed for Big Data and Cloud, new OpenPOWER Foundation members like Appentra, will be able to add their own innovations on top of the technology to create new applications that capitalize on emerging workloads.”
Parallware: LLVM-Based Tool for Guided Parallelization with OpenMP
December 19, 2016 by

Manuel Arenaz from Appentra presented this talk at the OpenMP booth at SC16. “Parallware is a new technology for static analysis of programs based on the production-grade LLVM compiler infrastructure. Using a fast, extensible hierarchical classification scheme to address dependence analysis, it discovers parallelism and annotates the source code with the most appropriate OpenMP & OpenACC directives.”
Maximize Parallelization with Threading On A Core
November 10, 2016 by

To get maximum parallelization for an application, not only must the application be developed to take advantage of multiple cores, but should also have the code in place to keep a number of threads working on each core. A modern processor architecture, such as the Intel Xeon Phi processor, can accommodate at least 4 threads for each core. “On the Intel Xeon Phi processor, each of the threads per core is known as a hyper-thread. In this architecture, all of the threads on a core progress through the pipeline simultaneously, producing results much more quickly than if just one thread was used. The processor decides which thread should progress, based on a number of factors, such as waiting for data from memory, instruction availability, and stalls.”
Parallware: Automatic Parallelization of Sequential Codes
October 3, 2014 by

“Parallware is a new source-to-source parallelizing commercial compiler based on a new disruptive, exclusive technology for automatic extraction of coarse-grain parallelism in sequential codes. Success cases reveal that it is effective and efficient in the auto-parallelization of full-scale real applications. Overall, Parallware improves programmability of modern HPC computers.”
Automatic Parallelization for GCC
October 13, 2009 by
Doug Eadline over at Cluster Monkey has the inside skinny on some auto parallelization technology from Russian company Optimitech that you can bolt on to gcc/gfortran One interesting application of the UTL technology is the Auto-Parallelizer — a tool that looks for parallelizable parts of sequential source code. Auto-Parallelizer is available as an addition to […]
In-Memory Computing Could Be an AI Inference Breakthrough
February 22, 2024 by

[CONTRIBUTED THOUGHT PIECE] In-memory computing promises to revolutionize AI inference. Given the rapid adoption of generative AI, it makes sense to pursue a new approach to reduce cost and power consumption by bringing compute in memory and improving performance.
Exascale: Pagoda Updates Programming with Scalable Data Structures and Aggressively Asynchronous Communication
August 25, 2023 by
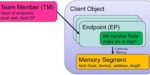
The Pagoda Project researches and develops software that programmers use to implement high-performance applications using the Partitioned Global Address Space model. The project is primarily funded by the Exascale Computing Project and interacts with partner projects….
LLNL: 9,000 Exascale Nodes for Power Grid Optimization
August 9, 2023 by
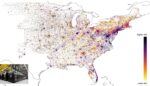
Ensuring the nation’s electrical power grid can function with limited disruptions in the event of a natural disaster, catastrophic weather or a manmade attack is a key national security challenge. Compounding the challenge of grid management is the increasing amount of renewable energy sources such as solar and wind that are continually added to the […]
UCSD Professor Leads COVID-19, Recommendation System Research Using ‘Hyperdimensional Computing’
July 18, 2023 by

Intel Labs has released a case study involving a professor at the University of California-San Diego, who for the past five years has led research efforts into what’s called hyperdimensional computing aimed at solving memory and data storage challenges. Hyperdimensional computing (HD) is a type of machine learning inspired by observations of how humans and […]
