
This fall, the Intel Extreme Performance Users Group (IXPUG) will host a free conference focused on key high-performance computing, artificial intelligence, and cloud computing topics.This guest post from Intel explores how AI and HPC are converging and and how the two areas of technology — as well as cloud computing — are converging.
Mellanox Rolls Out World’s Fastest Ethernet Storage Fabric Controller
August 6, 2018 by

Today Mellanox rolled out new BlueField-based storage controllers, offering “ultra-high performance” for Ethernet Storage Fabrics. “These BlueField storage controllers tightly-integrate flash connectivity, networking, and Arm processors to maximize performance and efficiency, while eliminating the need for a separate CPU in storage and hyperconverged appliances. This makes them perfect for connecting and virtualizing the fastest non-volatile storage.”
XSEDE allocates $7.3M worth of computing time to U.S. Researchers
July 24, 2018 by

“XSEDE has awarded 145 deserving research teams at 109 universities and other institutions access to nearly two dozen NSF-funded computational and storage resources, as well as other services unique to XSEDE, such as the Extended Collaborative Support Services (ECSS). Total allocations this cycle, running July 1, 2018, through June 30, 2019, represent an estimated $7.3 million of time on multi-core, many-core, GPU-accelerated, and large-memory computing resources (which does not include additional consulting resources) – all at no cost to the researchers. Since its founding in 2011, XSEDE and XSEDE 2.0 have allocated an estimated $270M of computing time.”
How to Become a Dynamic Technology Leader
July 12, 2018 by

The difference between a digitally dynamic business, and one who can’t keep up, is the inclusion of a capable technology leader. As the role has evolved, so too have the demands on Chief Information Officers. “Awareness of digital systems is now a key contribution to developing business strategy in several areas, including operations, expansion and marketing. Uncover the skills for success today.”
Penguin Computing Showcases Accelion managed data access platform
June 27, 2018 by
Today Penguin Computing announced the availability of the Accelion managed data access platform, a complete, managed file transfer and remote access solution that gives global, cross-functional teams the ability to work with vast amounts of geographically dispersed data and do so with greater speed, security, reliability and accessibility while unifying operations and accelerating collaboration. “For the first time, Penguin Computing customers have the ability to work with remote data at record-setting speeds and mount remote storage and treat it as if it were local, even over high latency network connections. Because data movement is transparent to the application layer, this means that, in many cases, the customer may not need to make any workflow changes between working with local data and working with remote data. This can result in reduced delays in both processing time and time-to-insight.”
Call for Papers: High Performance Machine Learning Workshop – HPML 2018
May 9, 2018 by

The HPML 2018 High Performance Machine Learning Workshop has issued its Call for Papers. The event takes place September 24 in Lyon, France. “This workshop is intended to bring together the Machine Learning (ML), Artificial Intelligence (AI) and High Performance Computing (HPC) communities. In recent years, much progress has been made in Machine Learning and Artificial Intelligence in general.”
Broad Institute and Intel Advance Genomics
March 26, 2018 by

The Broad Institute of MIT and Harvard in collaboration with Intel, is playing a major role in accelerating genomic analysis. This guest post from Intel explores how the two are working together to ‘reach levels of analysis that were not possible before.’
“The Ultimate Trading Machine” from Penguin Computing sets Record for Low Latency
November 1, 2017 by
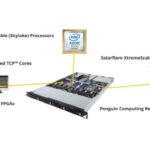
The world of High Frequency Trading is all about reducing latency to make money. At the recent STAC Summit in Chicago, a Penguin Computing device called The Ultimate Trading Machine achieved a record-low 98 nanosecond tick-to-trade latency, some 18% faster than the previous world record. “Facing tremendous pressures to optimize the transaction lifecycle, the financial services industry helps drive innovations in many core technologies. At Penguin Computing, we empower our customers with with open technology solutions that achieve performance requirements while keeping costs low and avoiding vendor lock-in. We are proud to join with our partners to deliver this Ultimate Trading Machine.”
NVIDIA Expands Deep Learning Institute
November 1, 2017 by

Today NVIDIA announced a broad expansion of its Deep Learning Institute (DLI), which is training tens of thousands of students, developers and data scientists with critical skills needed to apply artificial intelligence. “The world faces an acute shortage of data scientists and developers who are proficient in deep learning, and we’re focused on addressing that need,” said Greg Estes, vice president of Developer Programs at NVIDIA. “As part of the company’s effort to democratize AI, the Deep Learning Institute is enabling more developers, researchers and data scientists to apply this powerful technology to solve difficult problems.”
NVIDIA GPUs Power Fujitsu AI Supercomputer at RIKEN in Japan
October 31, 2017 by

Fujitsu has posted news that their new AI supercomputer at RIKEN in Japan is already being used for AI research. Called RAIDEN (Riken AIp Deep learning ENvironment), the GPU-accelerated Fujitsu system sports 4 Petaflops of processing power. “The RAIDEN supercomputer is built around Fujitsu PRIMERGY RX 2530 M2 servers with and 24 NVIDIA DGX-1 systems. With 8 NVIDIA Tesla GPUs per chassis, the DGX-1 includes access to today’s most popular deep learning frameworks.”

