
Tuning code has, for a long time, been an art. Knowing what to look for and how to correct inefficiencies in serious numerical computations has not been easy for most programmers. It’s often hard to even know which tool to start with. Which is why the Intel® VTune™ Amplifier Application Performance Snapshot could prove to be a great way to get an instant summary of an application’s performance characteristics and issues.
Learn What to Do Next with Intel VTune Amplifier Application Performance Snapshot
October 9, 2018 by
Intel Performance Libraries Accelerate Python Performance for HPC and Data Science
September 19, 2018 by

Python is now the most popular programming language, according to IEEE Spectrum’s fifth annual interactive ranking of programming languages, ahead of C++ and C. Recent Intel Distributions for Python show that real HPC performance can be achieved with compilers and library packages optimized for the latest Intel architectures. Moreover, the library packages targeted for big data analysis and numerical computation included in this distribution now support scaling for multi-core and many-core processors as well as distributed cluster and cloud infrastructures.
Use Intel Media SDK to Build Cross-Platform High-Quality Video Workflows
August 3, 2018 by
The latest release of Intel® Media SDK offers a single, cross-platform, GPU-enabled API for building optimized media and video applications from PC’s to workstations and into the cloud.
Deep Learning Open Source Framework Optimized on Apache Spark*
July 9, 2018 by
Intel recently released BigDL. It’s an open source, highly optimized, distributed, deep learning framework for Apache Spark*. It makes Hadoop/Spark into a unified platform for data storage, data processing and mining, feature engineering, traditional machine learning, and deep learning workloads, resulting in better economy of scale, higher resource utilization, ease of use/development, and better TCO.
Maximizing Performance of HiFUN* CFD Solver on Intel® Xeon® Scalable Processor With Intel MPI Library
June 12, 2018 by
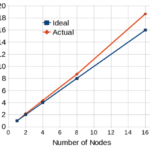
The HiFUN CFD solver shows that the latest-generation Intel Xeon Scalable processor enhances single-node performance due to the availability of large cache, higher core density per CPU, higher memory speed, and larger memory bandwidth. The higher core density improves intra-node parallel performance that permits users to build more compact clusters for a given number of processor cores. This permits the HiFUN solver to exploit better cache utilization that contributes to super-linear performance gained through the combination of a high-performance interconnect between nodes and the highly-optimized Intel® MPI Library.
Data Compression Optimized with Intel® Integrated Performance Primitives
May 21, 2018 by

Intel® Integrated Performance Primitives (Intel IPP) offers the developer a highly optimized, production-ready, library for lossless data compression/decompression that targets image, signal, and data processing, and cryptography applications. The Intel IPP optimized implementations of the common data compression algorithms are “drop-in” replacements for the original compression code.
Intel AVX Gives Numerical Computations in Java a Big Boost
March 22, 2018 by
Recent Intel® enhancements to Java enable faster and better numerical computing. In particular, the Java Virtual Machine (JVM) now uses the Fused Multiply Add (FMA) instructions on Intel Intel Xeon® PhiTM processors with Advanced Vector Instructions (Intel AVX) to implement the Open JDK9 Math.fma()API. This gives significant performance improvements for matrix multiplications, the most basic computation found in most HPC, Machine Learning, and AI applications.
Intel MKL Speeds Up Automated Driving Workloads on the Intel Xeon Processor
March 8, 2018 by
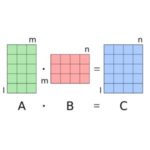
The automated driving developer community typically uses Eigen*, a C++ math library, for the matrix operations required by the Extended Kalman Filter algorithm. EKF usually involves many small matrices. However most HPC library routines for matrix operations are optimized for large matrices. “Intel MKL provides highly-tuned xGEMM function for matrix-matrix multiplication, with special paths for small matrices. Eigen can take advantage of Intel MKL through use of a compiler flag. A significant speedup results when using Eigen and Intel MKL and compiling the automated driving apps with the latest Intel C++ compiler.”
Intel MKL Compact Matrix Functions Attain Significant Speedups
February 22, 2018 by
The latest version of Intel® Math Kernel Library (MKL) offers vectorized compact functions for general and specialized matrix computations of this type. These functions rely on true SIMD (single instruction, multiple data) matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats.
Vectorization Now More Important Than Ever
February 8, 2018 by
Vectorization, the hardware optimization technique synonymous with early vector supercomputers like the Cray-1 (1975), has reappeared with even greater importance than before. Today, 40+ years later, the AVX-512 vector instructions in the most recent many-core Intel Xeon and Intel® Xeon PhiTM processors can increase application performance by 16x for single-precision codes.

