
Lawrence Berkeley National Laboratory has announced that national lab and university researchers recently released two papers introducing new methods of data storage and analysis to make quantum computing more practical and exploring how visualization helps in understanding quantum computing. “This work represents significant strides in understanding and harnessing current quantum devices for data encoding, processing, and visualization,” […]
Stanford AI Index: Lax LLM Reponsibility, AI for Science Accelerates, Impact on Workers, US Leads China in Models
April 16, 2024 by Leave a Comment
The AI Index Report from Stanford’s Institute for Human-Centered AI is out, it’s an annual, thoroughgoing snapshot of the state of AI begun by the HAI in 2019. This year’s edition presents new estimates on AI training….
Microsoft and NVIDIA Together Advance AI
April 16, 2024 by Leave a Comment

[SPONSORED GUEST ARTICLE] Think of the Microsoft Azure cloud platform as analogous to a general contractor who brings together the most skilled and knowledgeable artisans, technologically speaking, offering the latest and most powerful advanced AI capabilities. This would include the latest NVIDIA AI hardware….
NeuReality Launches Developer Portal for NR1 AI Inference Platform
April 16, 2024 by Leave a Comment
SAN JOSE — April 16, 2024 — NeuReality, an AI infrastructure technology company, announced today the release of a software developer portal and demo for installation of its software stack and APIs. The company said the announcement marks a milestone since delivery of its 7nm AI inference server-on-a-chip, the NR1 NAPU, and bring up of […]
Former Intel Executive Thomas Lantzsch Joins Canatu Board
April 16, 2024 by Leave a Comment

VANTAA, FINLAND, April 16, 2024 — Canatu, a developer of carbon nanotubes (Canatu CNTs) and manufacturing equipment for the semiconductor and automotive industries, today announced the appointment of former Intel executive Thomas Lantzsch to Canatu’s Board of Directors. He has more than 40 years of experience as an executive business leader across Fortune 500 companies […]
Accelsius Announces NeuCool Direct Liquid Cooling
April 15, 2024 by Leave a Comment
AUSTIN, Texas – Accelsius, whose patented two-phase direct-to-chip liquid cooling systems enable high-performance computing and compute density for data center and edge computer operators, today announced NeuCool, its in-rack solution that delivers unmatched thermal performance, the company said. With a capacity that has been tested beyond 1,500 watts per server chip (CPU, GPU, hot components), […]
Los Alamos Announces Nvidia-HPE AI Supercomputer ‘Venado’
April 15, 2024 by Leave a Comment

Venado’s computing capacity will house 2,560 direct, liquid-cooled Grace Hopper Superchips in the exascale-class HPE Cray EX supercomputer. The system will also use 920 Nvidia Grace CPU Superchips, making it the first large-scale system with Nvidia Grace CPU superchips deployed….
HPC News Bytes 20240415: Intel Gaudi 3, Meta’s MTIA Chip, Easing GPU Shortages, AI Category Theory, China’s Growth Strategy
April 15, 2024 by Leave a Comment

Happy Tax Day to you! Here’s a quck (6:23) romp through recent news from the world of HPC-AI, including: Intel’s Gaudi 3 GPU and Xeon-6 CPU, Meta’s new accelerator chip, GPU shortage easing….
Exaion and PINQ² to Launch the HPC-Quantum Platform in Quebec
April 12, 2024 by Leave a Comment
Montreal and Paris, April 12, 2024: Exaion, a Canadian subsidiary of the EDF Group (Électricité de France), a developer of digital service platforms aimed at eco-responsibility1, and PINQ² (Québec Digital and Quantum Innovation Platform), a non-profit organization created by the Quebec government and the University of Sherbrooke, announced plans to launch by the end of […]
NTT: Photonics Network Connects Data Centers in U.S. and U.K.
April 11, 2024 by Leave a Comment
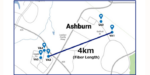
NTT Corporation (NTT) and NTT DATA announced the successful demonstration of All-Photonics Network (APN)-driven connections between data centers in the United States and the United Kingdom. In the U.K., NTT connected data centers north and east of London….

