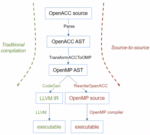
By Rob Farber, contributing writer for the Exascale Computing Project Clacc is a Software Technology development effort funded by the US Exascale Computing Project (ECP) PROTEAS-TUNE project to develop production OpenACC compiler support for Clang and the LLVM Compiler Infrastructure Project (LLVM). The Clacc project page notes, “OpenACC support in Clang and LLVM will facilitate the programming of GPUs and other accelerators in DOE applications, […]
Xilinx Acquires Falcon Computing for Software Programmability and Expand Developer Community
December 1, 2020 by
SAN JOSE, Calif. — Xilinx, Inc. (NASDAQ: XLNX) today announced it has acquired Falcon Computing Solutions, a privately-held leading provider of high-level synthesis (HLS) compiler optimization technology for hardware acceleration of software applications. The acquisition will make adaptive computing more accessible to software developers by enhancing the Xilinx Vitis Unified Software Platform with automated hardware-aware optimizations. […]
Helping the Compiler Speed Intel Xeon Phi
June 16, 2016 by
The vector parallel capabilities of the Intel Xeon Phi coprocessor are similar in many ways with vectorizing code for the main CPU. The performance improvement when coding smartly and using the tools available can be tremendous. Since the Intel Xeon Phi coprocessor can show very large gains in performance due to its extra wide processing units. “Although it is time consuming to look at each and every loop in a large application, by doing so, and both telling the compiler what to do, and letting the compiler do its work, performance increases can be quite large, leading to shorter run times and/or more complete results.”
Compiler Directives for High Performance Computing
June 9, 2016 by

“Directives can be used as hints to the compiler to vectorize a loop. The developer would have better knowledge of any dependencies that a compiler, which must adhere to a number of rules when deciding if a loop can be vectorized. Directives force the compiler to vectorize, based on the knowledge of the developer, thus, if something does not work correctly, it is the responsibility of the developer to fix it, rather than blame the compiler.”
Modernizing Code with the Intel Vectorization Advisor
March 17, 2016 by
Threading plus vectorization together can increase the performance of an application more than one technique or the other. Threading and vectorizing an application are two techniques that are known to increase the performance of an application using modern CPUs and coprocessors. However, a deep understanding of the application is needed in order to make the decisions needed and to rewrite portions of the application to take advantage of these techniques. In cases where the developer might not be familiar with the code an automated tools such as the Intel Vectorization Advisor can assist the developer.
PreFetch for Intel Xeon Phi – Part 2
March 3, 2016 by

“An interesting aspect to prefetching is the distance ahead of the data that is being used to prefetch more data. This is a critical parameter for success and can be defined as how many iterations ahead to issue a prefetch instruction, and can be referred to as the distance. A compiler will automatically determine the distance to prefetch, and can be determined by looking at the compiler optimization reports.”
N-Body Methods Optimization
May 28, 2015 by

“N-Body problems compare the interaction of N-bodies against N-bodies, which results in calculations of the order of N2. As this can be computationally very expensive, but a well understood process, techniques and optimizations can be performed on application code using compiler directives and easy to understand techniques.”

