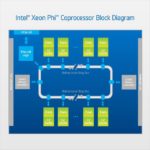
“The major functionality of the Intel Xeon Phi coprocessor is a chip that does the heavy computation. The current version utilizes up to 16 channels of GDDR5 memory. An interesting notes is that up to 32 memory devices can be used, by using both sides of the motherboard to hold the memory. This doubles the effective memory availability as compared to more conventional designs.”
Using Libraries in Offload Mode
August 4, 2016 by

The ability to develop applications independent of the hardware availability at run time is a very important concept that enables developers to take advantage of the latest and greatest processing and coprocessing power. Without having to make run time checks on hardware availability is critical to a smooth running HPC environment.
Offloading Application Segments to Intel Xeon Phi Coprocessors
July 21, 2016 by

Offloading to a coprocessor does need to be considered carefully, due to the memory transfer requirements. When the data that is to be worked on resides in the memory of the main system, that data must be transferred to the coprocessor’s memory. The challenge arises because memory is not physically shared between the main system and the coprocessor.
“There are two offload models that the developer must consider when programming an application. The first is the non-shared memory model, and the second is the virtual shared memory model. Both of these models can be used in the same application.”
Compiler Directives for High Performance Computing
June 9, 2016 by

“Directives can be used as hints to the compiler to vectorize a loop. The developer would have better knowledge of any dependencies that a compiler, which must adhere to a number of rules when deciding if a loop can be vectorized. Directives force the compiler to vectorize, based on the knowledge of the developer, thus, if something does not work correctly, it is the responsibility of the developer to fix it, rather than blame the compiler.”
Data Layout for High Performance
June 2, 2016 by
For maximum performance, data needs to flow into and out of the vectorization units. There are a few things to remember regarding laying out the data to gain high performance. These include, data layout, alignment, prefetching, and store operations. “Prefetching is also extremely important in HPC applications that use coprocessors. If the vectors are aligned, then the data can be streamed to the math units very efficiently, with data being prefetched, rather than the system having to load registers from various memory storage.”
Cosmic Microwave Background Analysis with Intel Xeon Phi
December 10, 2015 by
“Modal is a cosmological statistical analysis package that can be optimized to take advantage of a high number of cores. The inner product computations with Modal can be run on the Intel Xeon Phi coprocessor. As a base, the entire simulation took about 6 hours on the Intel Xeon processor. Since the inner calculations are independent from each other, this lends to using the Intel Xeon Phi coprocessor.”

