
From Wall Street to the Great Wall, enterprises and institutions of all sizes are faced with the benefits – and challenges – promised by ‘Big Data’. But before users can take advantage of the near limitless potential locked within their data, they must have affordable, scalable and powerful software tools to manage the data.
Why Does Hadoop Have Such an Uncomfortable Fit in HPC?
May 19, 2014 by

“The evolution of Hadoop has very much been a backwards one; it entered HPC as a solution to a problem which, by and large, did not yet exist. As a result, it followed a common, but backwards, pattern by which computer scientists, not domain scientists, get excited by a new toy and invest a lot of effort into creating proof-of-concept codes and use cases. Unfortunately, this sort of development is fundamentally unsustainable because of its nucleation in a vacuum, and in the case of Hadoop, researchers moved on to the next big thing and largely abandoned their model applications as the shine of Hadoop faded.”
Progress Report on Efficient Integration of Lustre and Hadoop/YARN
April 24, 2014 by

Using Hadoop with Lustre provides several benefits, including: Lustre is a real parallel file system, which enables temporary or intermediate data to be stored in parallel on multiple nodes reducing the load on single nodes. In addition, Lustre has its own network protocol, which is more efficient for bulk data transfer than the HTTP protocol. Additionally, because Lustre is a shared file system, each client sees the same file system image, so hardlinks can be used to avoid data transfer between nodes.
Porting Hadoop to HPC
February 23, 2014 by

Ralph H. Castain from Intel presented this talk at the Adaptive Computing booth at SC13. “The solution allows customers to leverage both their HPC and big data investments in a single platform, as opposed to operating them in siloed environments. The convergence between big data and HPC environments will only grow stronger as organizations demand data processing models capable of extracting the results required to make data-driven decisions.”
New Moab Task Manager & Support for Intel HPC Distribution for Hadoop
December 7, 2013 by

New innovations from Adaptive Computing include: Moab Task Manager, a localized decision-making tool within Moab’s HPC Suite that enables high-speed throughput on short computing jobs. Adaptive has also announced a partnership with Intel to integrate Moab/TORQUE workload management software with the Intel HPC Distribution for Apache Hadoop software, which combines the Intel Distribution for Apache Hadoop software with the Intel Enterprise Edition of Lustre software.
Using PBS to Schedule MapReduce Jobs Accessing OrangeFS
October 4, 2013 by
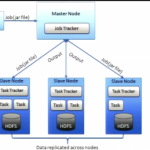
Using PBS Professoinal and a customized version of myHadoop has allowed researchers at Clemson University to submit their own Hadoop MapReduce jobs on the “Palmetto Cluster”. Now, researchers at Clemson can run their own dedicated Hadoop daemons in a PBS scheduled environment as needed.

