
The performance of distributed memory MPI applications on the latest highly parallel multi-core processors often turns out to be lower than expected. Which is why hybrid applications using OpenMP multithreading on each node and MPI across nodes in a cluster are becoming more common. This sponsored post from Intel, written by Richard Friedman, depicts how to boost performance for hybrid applications with multiple endpoints in the Intel MPI Library.
Achieving the Best QoE: Performance Libraries Accelerate Code Execution
March 12, 2019 by

The increasing consumerization of IT means that even staid business applications like accounting need to have the performance and ease of use of popular consumer apps. Fortunately, developers now have access to a powerful group of libraries that can instantly increase application performance – with little or no rewriting of older code. Here’s a quick rundown of Intel-provided libraries and how to get them.
Maximizing Performance of HiFUN* CFD Solver on Intel® Xeon® Scalable Processor With Intel MPI Library
June 12, 2018 by
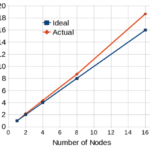
The HiFUN CFD solver shows that the latest-generation Intel Xeon Scalable processor enhances single-node performance due to the availability of large cache, higher core density per CPU, higher memory speed, and larger memory bandwidth. The higher core density improves intra-node parallel performance that permits users to build more compact clusters for a given number of processor cores. This permits the HiFUN solver to exploit better cache utilization that contributes to super-linear performance gained through the combination of a high-performance interconnect between nodes and the highly-optimized Intel® MPI Library.

