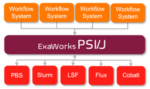
ExaWorks is an Exascale Computing Project (ECP)–funded project that provides access to hardened and tested workflow components through a software development kit (SDK). Developers use this SDK and associated APIs to build and deploy production-grade, exascale-capable workflows on US Department of Energy (DOE) and other computers. The prestigious Gordon Bell Prize competition highlighted the success of the ExaWorks SDK when the Gordewinner and two of three finalists in the 2020 Association for Computing Machinery (ACM) Gordon Bell Special Prize for High Performance Computing–Based COVID-19 Research competition leveraged ExaWorks technologies.
Superior Performance Commits Kyoto University to CPUs Over GPUs
July 25, 2016 by

In this special guest feature, Rob Farber writes that a study done by Kyoto University Graduate School of Medicine shows that code modernization can help Intel Xeon processors outperform GPUs on machine learning code. “The Kyoto results demonstrate that modern multicore processing technology now matches or exceeds GPU machine-learning performance, but equivalently optimized software is required to perform a fair benchmark comparison. For historical reasons, many software packages like Theano lacked optimized multicore code as all the open source effort had been put into optimizing the GPU code paths.”

