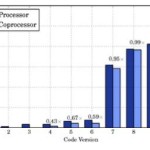
“NWPerf is software that can measure and collect a wide range of performance data about an application or set of applications that run on a cluster. With minimal impact on performance, NWPerf can gather historical information that then can be used in a visualization package. The data collected includes the power consumption using the Intelligent Platform Management Interface (IPMI) for the Intel Xeon processor and the libmicmgmt API for the Intel Xeon Phi coprocessor. Once the data is collected, and using some data extraction mechanisms, it is possible to examine the power used across the cluster, while the application is running.”
Army Unveils Excalibur Cray XC40 Supercomputer
October 22, 2015 by

On Oct. 16, the U.S. Army introduced Excalibur, its newest supercomputer. Currently ranked at #26 on the TOP500, the Cray XC40 system will help ensure Soldiers have the technological advantage on the battlefield, officials said.
Researching Origins of the Universe at the Stephen Hawking Centre for Theoretical Cosmology
October 14, 2015 by
In this special guest feature, Linda Barney writes that researchers at the University of Cambridge are using an Intel Xeon Phi coprocessor-based supercomputer from SGI to accelerate discovery efforts. “We have managed to modernize and optimize the main workhorse code used in the research so it now runs at 1/100-1/1000 of the original runtime. This allows us to tackle problems which would have taken unfeasibly long to solve. Secondly, it has opened windows for previously unthinkable research, namely using the MODAL code in cosmological parameter search: this is a problem which is constantly being solved in an iterative process, but adding the MODAL results to the process has only become possible with the improved performance.”
Video: TotalView Parallelizes Code at ISC 2015
July 28, 2015 by

“TotalView breaks down barriers to understanding what’s going on with your HPC and supercomputing applications. Purpose-built for multicore and parallel computing, TotalView provides a set of tools providing unprecedented control over processes and thread execution, along with deep visibility into program states and data.”
Video: Algorithms for Extreme-Scale Systems
July 5, 2015 by

Bill Gropp from the University of Illinois at Urbana-Champaign presented this talk at the Blue Waters Symposium. “The large number of nodes and cores in extreme scale systems requires rethinking all aspects of algorithms, especially for load balancing and for latency hiding. In this project, I am looking at the use of nonblocking collective routines in Krylov methods, the use of speculation and large memory in graph algorithms, the use of locality-sensitive thread scheduling for better load balancing, and model-guided communication aggregation to reduce overall communication costs. This talk will discuss some current results and future plans, and possibilities for collaboration in evaluating some of these approaches.”
Radio Free HPC Previews ISC 2015
June 29, 2015 by

In this podcast, the Radio Free HPC team previews the ISC 2015 conference, which takes place July 12-16 in Frankfurt, Germany. In addition to a great technical program, the conference will feature an exhibition, tutorials, workshops, and a Student Cluster Competition.
HPC People on the Move – Long, Hot Summer Edition
June 25, 2015 by

Dr. Lewey reports on who’s jumping ship and moving on up in high performance computing.
Video: Introduction to Docker
May 26, 2015 by

In this video, Docker Founder and CTO Soloman Hykes explains what Docker is and why developers like it. “Docker is an open-source engine that automates the deployment of any application as a lightweight, portable, self-sufficient container that will run virtually anywhere.”
Attacking HIV with Titan and Blue Waters
May 13, 2015 by
“The highly parallel molecular dynamics code NAMD was was one of the first codes to run on a GPU cluster when G80 and CUDA were introduced in 2007, and is now used to perform petascale biomolecular simulations, including a 64-million-atom model of the HIV virus capsid, on the GPU-accelerated Cray XK7 Blue Waters and ORNL Titan machines.”
Video: Docker, Monitoring, and SLURM Dashboards
May 7, 2015 by

“Based on a containerized HPC environment this talk shows of a state-of-the-art stack including performance monitoring, log event handling and GraphDB based inventory to provide insights into what is going on within a SLURM cluster. The framework used is QNIBTerminal incorporating the ELK stack, a graphite backend and neo4j as a GraphDB.”

