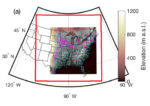
Researchers are using TACC supercomputers to map out a path towards growing wind power as an energy source in the United States. “This research is the first detailed study designed to develop scenarios for how wind energy can expand from the current levels of seven percent of U.S. electricity supply to achieve the 20 percent by 2030 goal outlined by the U.S. Department of Energy National Renewable Energy Laboratory (NREL) in 2014.”
Supercomputing Transportation System Data using TACC’s Rustler
February 14, 2017 by

Over at TACC, Faith Singer-Villalobos writes that researchers are using the Rustler supercomputer to tackle Big Data from self-driving connected vehicles (CVs). “The volume and complexity of CV data are tremendous and present a big data challenge for the transportation research community,” said Natalia Ruiz-Juri, a research associate with The University of Texas at Austin’s Center for Transportation Research. While there is uncertainty in the characteristics of the data that will eventually be available, the ability to efficiently explore existing datasets is paramount.
Podcast: Supercomputing Better Soybeans
August 17, 2016 by
In this TACC Podcast, Researchers describe how XSEDE supercomputing resources are helping them grow a better soybean through the SoyKB project based from the University of Missouri-Columbia. “The way resequencing is conducted is to chop the genome in many small pieces and see the many, many combinations of small pieces,” said Xu. “The data are huge, millions of fragments mapped to a reference. That’s actually a very time consuming process. Resequencing data analysis takes most of our computing time on XSEDE.”
Podcast: Speeding Through Big Data with the Wrangler Supercomputer
March 11, 2016 by

In this TACC Podcast, Jorge Salazar reports that scientists and engineers at the Texas Advanced Computing Center have created Wrangler, a new kind of supercomputer to handle Big Data.
Podcast: Big Data on the Wrangler Supercomputer
December 11, 2015 by

In this TACC podcast, Niall Gaffney from the Texas Advanced Computing Center discusses the Wrangler supercomputer for data-intensive computing. “We went to propose to build Wrangler with (the data world) in mind. We kept a lot of what was good with systems like Stampede, but then added new things to it like a very large flash storage system, a very large distributed spinning disc storage system, and high speed network access to allow people who have data problems that weren’t being fulfilled by systems like Stampede and Lonestar to be able to do those in ways that they never could before.”
TACC’s “Wrangler” Uses DSSD Technology for Data-Intensive Computing
April 22, 2015 by
Today the Texas Advanced Computing Center announced that the Wrangler data analysis and management supercomputing system is now in early operations for the open science community. Supported by a grant from the NSF, Wrangler uses innovative DSSD technology for data-intensive computing.

