The GridGain In-Memory computing platform works to deliver speed and scalability for your large data needs. The platform, which was recently highlighted in a new white paper from GridGain Systems, is built on the Apache Ignite open source project.

Download the full report.
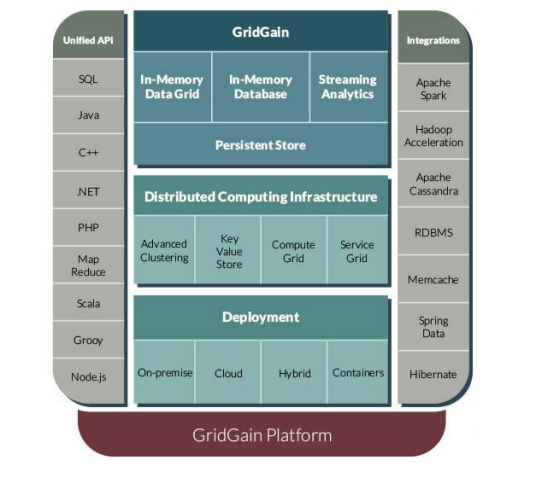
The new white paper offers an overview of the product and different software editions, as well as its key features and architecture. Readers will also learn about key integrations for the platform, including Apache Spark and Apache Cassandra.
What makes GridGain stand out? Unlike in-memory databases, GridGain can work on top of existing databases and requires no rip-and-replace or any changes to an existing RDBMS. And GridGain can even automatically integrate with different RDBMS systems, such as Oracle, MySQL, Postgres, DB2, Microsoft SQL server and others.
GridGain also offers more than in-memory data grids. This is just one of the capabilities GridGain offers; it also supports HPC/MPP processing, distributed SQL, streaming, clustering and Hadoop acceleration. GridGain can also be deployed as a distributed, transactional in-memory database, according to the report that serves as an introduction to the GridGain platform.
GridGain comes into three software editions:
- The GridGain Professional Edition, which is a binary build of Apache Ignite, created by GridGain, which includes optional LGPL dependencies.
- The GridGain Enterprise Edition adds enterprise-grade features, including data center replication, enterprise grade security, rolling upgrades, and more.
- The GridGain Ultimate Edition includes all the features of the GridGain Enterprise Edition plus a Cluster Snapshots feature for automated backups of the GridGain cluster.
As to the platform’s architecture, GridGain is JVM-based distributed middleware software. See the full white paper for key features, including in-memory data grid, in-memory database, in-memory compute grid, in-member streaming, in-memory hadoop acceleration, advanced clustering, unified API and many more. In fact, the GridGain unified API supports a wide variety of common protocols for the application layer to access data, including SQL, JAVA, C++, .NET, PHP, MapReduce, Scala, Groovy and Node.js.
The GridGain large scale, distributed in-memory framework offers transactional and analytical applications performance gains of 100 to 1,000 times faster throughput and/or lower latencies.
The GridGain Persistent Store is also unique. GridGain describes this capability as “a distributed ACID and ANSI-99 SQL-compliant disk store available in Apache Ignite that transparently integrates with GridGain as an optional disk layer.”
This means that you do not need to keep all active data in memory or warm up your RAM following a cluster restart to utilize the system’s in-memory computing capabilities.
In conclusion, GridGain in-memory computing comprises, in one “well-integrated framework,” the following capabilities:
- An in-memory data grid
- An in-memory transactional SQL database
- An in-memory compute grid
- In-memory streaming processing
- An in-memory service grid
- In-memory acceleration for Hadoop
Download the new white paper today, “Introducing the GridGain In-Memory Computing Platform,” to find out if GridGain is the right choice for you.
