We continue our five-part series on the steps to take before launching a machine learning startup. The complete report, available here, covers how to get started, choose a framework, decide what applications and machine learning technology to use, and more. This post also includes a few technology options for enterprises looking to explore machine learning.

AI starter kit
What is it?
Dell EMC PowerEdge C4130 server, a flexible, dense 1U rack server optimized for GPUs and co-processors.
What does it do?
Put simply, the PowerEdge C4130 server handles the most demanding workloads, including high-performance computing, data visualization and rendering.
Tech specs and features
- Five unique configurations, including up to four 300W double-width NVIDIA Tesla GPU accelerators in just 1U of space
- Up to 2x Intel Xeon processor E5 family
- Red Hat Enterprise Linux operating system
- Memory: DDR4 DIMMs at up to 2400MT/s; 16 DIMM slots: 4GB/8GB/16GB/32GB/64GB
- Storage of up to Up to 2 x 1.8” SATA SSD boot drives. Optional data drive tray supports up to 4 x 2.5” SAS/SATA drives, and optional 12Gb/s SAS and 6Gb/s SATA (with PERC9 card).
- Optional internal controller: PERC H330, H730, H730P and H810
- 2x 1GbE network controller
- Power: 1100W, 1600W, 2000W hot-plug PSU; redundant PSU (1+1) op on available

Dell EMC PowerEdge C4130 server
How Will it Help Me?
The PowerEdge C4130 server covers a combination of flexibility, efficiency and performance in a compact package that reduces cost and management requirements. The balanced architecture ensures that workload requirements are met through a flexible combination of accelerator, processor, memory and bandwidth.
NVIDIA Tesla P100

NVIDIA Tesla P100
What is it?
NVIDIA Tesla P100 GPU accelerator for PCIe-based servers, and NVIDIA NVLink-optimized servers
What does it do?
By tapping into the new NVIDIA PascalTM GPU architecture—an architecture that’s purpose-built for computers that embrace deep learning—these accelerators deliver the world’s fastest compute node. This higher performance dramatically increases throughput without increasing the cost.
Tech specs and further features
- Enables a single node to replace half a rack of CPU nodes
- Compute and data are integrated on the same package using Chip-on-Wafer-on-Substrate with HBM2 technology for 3X memory performance over the previous-generation on architecture
- Pascal delivers more than 18.7 TeraFLOPS of FP16, 4.7 TeraFLOPS of double-precision, and 9.3 TeraFLOPS of single-precision performance
- A server node with NVIDIA NVLink can interconnect up to eight Tesla P100s at 5X the bandwidth of PCIe.
- A single GPU-accelerated node powered by four Tesla P100s interconnected with PCIe replaces up to 32 CPU nodes
- Applications can scale beyond the GPUs physical memory limit to almost limitless levels without losing performance, thanks to simpler programming and computing performance tuning.
How will it help me?
Instead of focusing efforts on managing data movements, developers are free to focus more on tuning for performance. Essentially, with a reduction in time to results from months to days you’ll be able to do more, in less me, and save money while you’re at it.
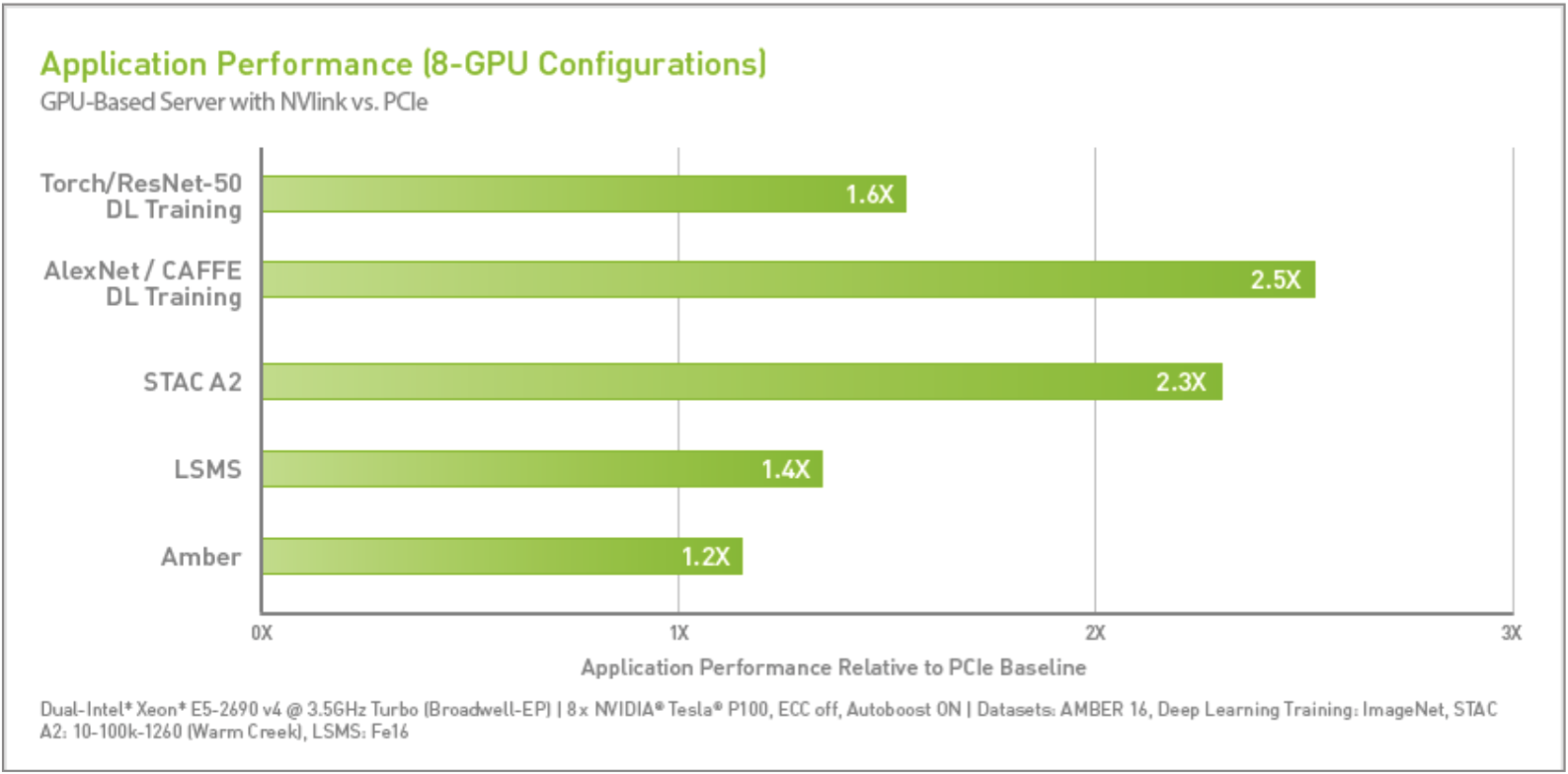
NVIDIA NVLink
What is it?
NVIDIA NVLinkTM is a high-bandwidth, energy- efficient interconnect that supports ultra-fast communication between the CPU and GPU, and between GPUs.
What does it do?
It enables data sharing at speeds between five and 12 mes faster than the traditional PCIe Gen3 interconnect, meaning that applications get a dramatic boost in performance.
NVIDIA NVLink will let data move between GPUs and CPUs five to 12 mes faster than they can today. Imagine what would happen to highway congestion in Los Angeles if the roads expanded from four lanes to 20.
Tech specs and further features
- Provides an energy-efficient, high-bandwidth path between the GPU and the CPU at data rates of at least 80 gigabytes per second or at least five times that of the current PCIe Gen3 x16
- GPUs and CPUs can quickly and seamlessly access each other’s memory
- Significant performance benefit for GPU-to-GPU (peer-to-peer) communications
- United Memory and NVIDIA NVLink represent a powerful combination for CUDA programmers
How will it help me?
The unique memory bandwidth and increased throughput enables more advanced modeling and techniques for data-parallel programs.
The resulting faster training and better scaling provides deep learning training models with a step up, especially when dealing with out-of-core computations (the input data is too large for the device memory of the GPU).
Future articles in the insideHPC guide on launching a machine learning startup will cover the following additional topics:
- What developers need to consider when exploring machine learning
- Inference systems
- The results of machine learning technology utilization
- What next? How to enter the world of machine learning
You can download the complete report, “insideHPC Special Report: Launch a Machine Learning Startup,” courtesy of Dell EMC and Nvidia.

