 In this video, from Andrew Gibiansky from Baidu describes baidu-allreduce, a newly released C library that enables faster training of neural network models across many GPUs. The library demonstrates the allreduce algorithm, which you can embed into any MPI-enabled application.
In this video, from Andrew Gibiansky from Baidu describes baidu-allreduce, a newly released C library that enables faster training of neural network models across many GPUs. The library demonstrates the allreduce algorithm, which you can embed into any MPI-enabled application.
The ring allreduce is a well-known algorithm from the field of high-performance computing but underused in deep learning. This technique enables near-linear speedup, scaling to dozens or even hundreds of GPUs. For example, using ring allreduce, SVAIL showed a 31x speed up in training neural networks, by scaling to 40 GPUs.
“Neural networks have grown in scale over the past several years, and training can require a massive amount of data and computational resources. To provide the required amount of compute power, we scale models to dozens of GPUs using a technique common in high-performance computing but underused in deep learning. This technique, the ring allreduce, reduces the amount of time spent communicating between different GPUs, allowing them to spend more of their time doing useful computation. Within Baidu’s Silicon Valley AI Lab, we have successfully used these techniques to train state-of-the art speech recognition models. We are excited to release our implementation of the ring allreduce as a library as well as a patch for TensorFlow, and we hope that by releasing these libraries we can enable the deep learning community to scale their models more effectively.”
The ring allreduce, a technique from the field of high-performance computing, allows us to efficiently average gradients in neural networks across many devices and many nodes. By using this bandwidth-optimal algorithm during training, you can drastically reduce the communication overhead and scale to many more devices, while still retaining the determinism and predictable convergence properties of synchronous stochastic gradient descent. The algorithm is network architecture and deep learning framework agnostic and can provide tangible and immediate benefits for the efficiency of data-parallel training, while also being fairly straight-forward and easy to implement.
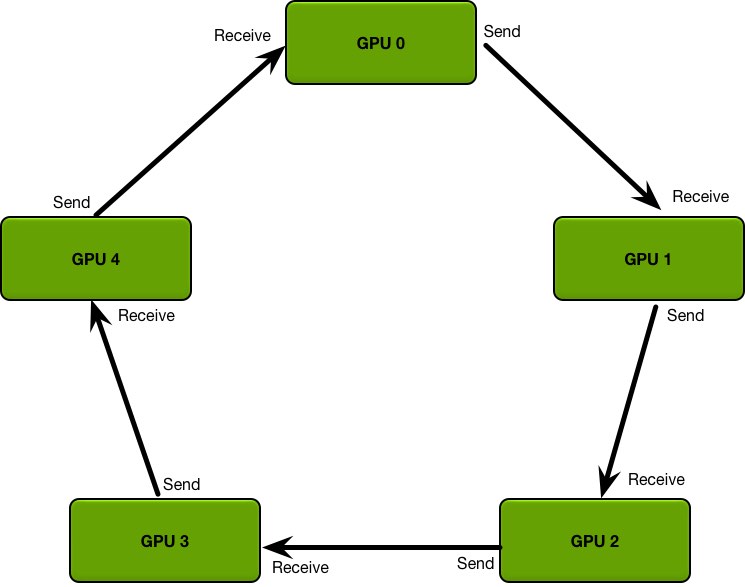 In order to make it easier for you to take advantage of these techniques, today we’re releasing baidu-allreduce, a C library demonstrating the allreduce algorithm which you can embed into any MPI-enabled application. In addition, we’ve integrated the allreduce into TensorFlow (see the tensorflow.contrib.mpi module for documentation).
In order to make it easier for you to take advantage of these techniques, today we’re releasing baidu-allreduce, a C library demonstrating the allreduce algorithm which you can embed into any MPI-enabled application. In addition, we’ve integrated the allreduce into TensorFlow (see the tensorflow.contrib.mpi module for documentation).

