Univa’s Robert Lalonde, Vice President and General Manager, Cloud, highlights how data management is key to today’s HPC hybrid cloud success.

Robert Lalonde, Vice President and General Manager, Univa.
While there are many benefits to leveraging the cloud for HPC, there are challenges as well. Along with security and cost, data handling is consistently identified as a top barrier. Data requirements vary by application, datasets are often large and accessing data across even the fastest WAN connection is orders of magnitude slower than accessing it locally. In this short article, we discuss the challenge of managing data in hybrid clouds, offer some practical tips to makes things easier, and explain how automation can play a key role in improving efficiency.
Diverse storage and data movement solutions in the cloud
As is the case with local clusters, there are a variety of cloud storage options including block storage, object storage, and elastic and parallel file systems. Unlike compute instances, storage pricing is usually complex. Pricing is usually tiered, and it depends on multiple factors including data volume, bandwidth, latency, quality-of-service, and data egress costs.
Just as there are many storage options, there are many approaches to moving, caching, and replicating data. For small datasets, users might use simple utilities such as rcp or scp and have the workload manager stage data in advance. Open-source rsync provides a simple way to keep local and remote file systems synchronized. Customers can use cloud-specific solutions such as AWS DataSync (for synchronizing local NFS files to AWS EFS or AWS S3), AWS FSx for Lustre or hybrid cloud file systems that employ connectors and caching such as Elastifile and Microsoft Avere vFXT.
Some practical tips to managing data in HPC Hybrid Clouds
As you devise your strategy for data handling in the cloud, here are some suggestions that can help you arrive at a better more cost-efficient solution.
- Ballpark your costs in advance: Before going too far down the road of detailed planning, it’s useful to develop a “back of the envelope” monthly cost model. Consider factors such as data volumes, transfer times, how long data will reside in file systems vs. object stores, etc. This will help you determine whether the solution you have in mind is feasible.
- Move the processing to the data: To state the obvious, the most efficient way to solve data handling challenges is to avoid them by moving the compute task to the data if you can. Workload managers can automate this process by shifting containerized workloads to local hosts or cloud instances tagged as having proximity to a needed dataset automatically.
- Use replication with care: Just because you can replicate your entire Petabyte file system to the cloud doesn’t mean you should. Replicate data selectively and move only the data needed by each workload. Avoid dormant cloud data and adjust your replication frequency considering that remote data only needs to be in sync when there is an application that needs it.
- Minimize costs with data tiering: Remember that different cloud storage tiers can have dramatically different costs. Rather than persisting data on expensive cloud file systems, leave data in a lower-cost object store when not in use.
- Treat storage as an elastic resource: We’re used to the idea that the number of cloud instances in a cluster can flex up and down, but we tend to think of cloud storage as static. Employ automation to provision file systems only when dynamic cloud instances need them, and shutdown them down after use.
Intelligent data handling is the key challenge
While there are a variety of cloud storage technologies and caching and synchronization solutions, the key challenge is controlling these components at runtime to deliver the best service at the lowest cost in a manner that is transparent to users.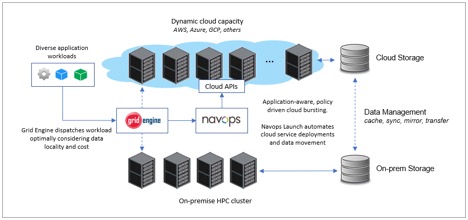
Navops Launch simplifies and optimizes the financial aspects of HPC deployments across multiple clouds with fast, workload-driven provisioning that sizes cloud footprint dynamically based on application demand. A built-in automation engine and applet facility allows for dynamic marshaling of cloud storage services. By combining application related metrics from Univa Grid Engine with usage and cost information extracted from the cloud provider, user-defined applets can make decisions at runtime related to data locality, data movement, and optimizing performance and cost.
You can learn more by reviewing our article on Data Management in the HPC Cloud or reading about new automation features in Navops Launch 1.0.
Robert Lalonde is Vice President and General Manager, Cloud, at Univa. Follow Lalonde @NavopsRob.
