Univa’s Robert Lalonde, Vice President and General Manager, Cloud, explores how to turbocharge your HPC hybrid cloud with tools like policy-based automation, and how closing the loop between workload scheduling and cloud-automation can drive higher performance and dramatic cost efficiencies.

Robert Lalonde, Vice President and General Manager, Univa.
While there are many advantages to running in the cloud, the issues can be complex. Users need to figure out how to securely extend on-premise clusters, devise solutions for data handling and constantly keep an eye on costs. In earlier articles, we’ve pointed out that using cloud efficiently requires automation – otherwise time spent on manual, tedious tasks and upside cloud cost surprises can undermine any advantages you’d hoped to achieve. Automation alone is not enough, however. Real gains in efficiency demand systems that can largely manage themselves, and this requires both automation and smart policies. In this article, we discuss how closing the loop between workload scheduling policies and cloud-automation can lead to new efficiency gains.
Workload Scheduling is Only Part of the Solution
When HPC professionals think about policy, we naturally think about scheduling policies in a workload manager. Scheduling policies help ensure that jobs are completed on time, resources are shared equitably, and user wait times are minimized. Workload managers, such as Univa Grid Engine have helped organizations realize dramatic gains in productivity, using a variety of sophisticated scheduling and resource sharing policies.
Cloud computing gives us the opportunity to fundamentally rethink our ideas around scheduling policies and how they relate to infrastructure.
In this traditional model, schedulers guided by policies play an elaborate game of Tetris, placing workloads on a fixed infrastructure and simultaneously satisfying as many constraints as possible. Administrators continually refine scheduling policies, but when the infrastructure is static, there is only so much the scheduler can do. If my job requires 16 Volta GPUs running across four singularity capable hosts for example, but I only have two suitable hosts, the scheduler can’t solve this problem. Inevitably, some jobs will fail to run while other infrastructure sits idle due to a mismatch between supply and demand.
In the past, we’ve focused on scheduling workload to adapt to available infrastructure. With clouds, we have the opportunity to turn this on its head and adapt the infrastructure to the workload.
Bringing policy to infrastructure management
Cloud computing gives us the opportunity to fundamentally rethink our ideas around scheduling policies and how they relate to infrastructure. When cloud instances, machine images, storage and networks are all soft-configurable, why not simply schedule infrastructure better suited to the workload? As examples:
- Rather than dispatching jobs to generic machines or instances, why not inspect the resource requirements for pending jobs dynamically and provision machine instances and images that exactly meet the workload requirement?
- If a frequently used application routinely requests eightcores and 64 GB of memory, but runtime monitoring shows that it consistently consumes only fourcores and 32 GB of memory, why not learn from experience and adjust the resource requirement downward to cut costs roughly in half?
- If a pending parallel job needs a cloud-resident data set and access to fast scratch storage, why not deploya parallel file system and suitable machine instances in the cloud for only the time they are needed and automatically migrate data to lower cost object storage when it is not in use?
- If it will take four hours to transfer data to the cloud and only two hours to do the work, we should decideat runtime to have the job run locally and consider bursting other jobs to the cloud instead.
Workload managers have allowed us to implement policies for some time, but there are clear opportunities for policy-based automation at the infrastructure and cloud management layers as well.
Closing the loop between applications and infrastructure
Navops Launch helps bridge applications and infrastructure with a sophisticated automation engine configurable through an intuitive Web UI. In Navops Launch, applets can be written that have access to the full set workload related objects and attributes visible to Univa Grid Engine, including things like jobs, queues, projects, users and groups. Navops Launch also exposes information about cluster and cloud environment attributes, key performance metrics and optional data from external systems as well. Automation applets can consider data from all of these sources and automatically perform actions at runtime, like re-configuring firewalls, changing machine instances, modifying jobs or manipulating data.
This architecture essentially “closes the loop” between workload management and infrastructure management, providing the scheduler and Navops Launch with the opportunity to share data, as well as co-operate on more sophisticated, automated policies.
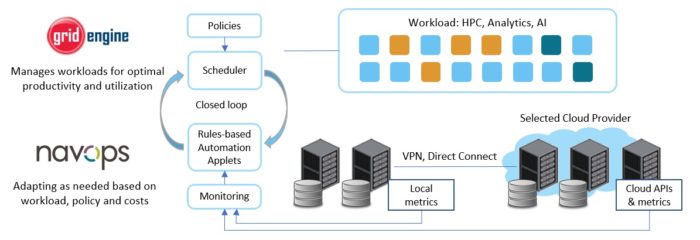
By combining application-related metrics from Univa Grid Engine with usage and cost information extracted from the cloud provider, user-defined applets can make better decisions related to data locality, data movement and optimizing performance and cost. With these powerful automation capabilities, Navops Launch can provide significant cost savings and make hybrid cloud migration and bursting simple and seamless.
Learn more about HPC Hybrid Cloud and new automation features in Navops Launch.
Robert Lalonde is the Vice President and General Manager, Cloud, at Univa.

