![]() Today, every high-performance computing (HPC) workload running globally faces the same crippling issue: Congestion in the network.
Today, every high-performance computing (HPC) workload running globally faces the same crippling issue: Congestion in the network.
Congestion can delay workload completion times for crucial scientific and enterprise workloads, making HPC systems unpredictable and leaving high-cost cluster resources waiting for delayed data to arrive. Despite various brute-force attempts to resolve the congestion issue, the problem has persisted. Until now.
In this paper, Matthew Williams, CTO at Rockport Networks, explains how recent innovations in networking technologies have led to a new network architecture that targets the root causes of HPC network congestion, specifically:
- Why today’s network architectures are not a sustainable approach to HPC workloads
- How HPC workload congestion and latency issues are directly tied to the network architecture
- Why a direct interconnect network architecture minimizes congestion and tail latency
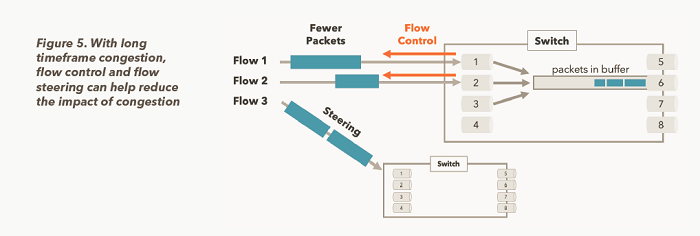
Rockport Networks understands the root causes and ramifications of congestion and latency, particularly tail latency, in HPC compute clusters, and has designed a distributed and embeddable switchless network architecture that resolves these issues.
Download this white paper, “It’s Time to Resolve the Root Cause of Congestion,” sponsored by Rockport Networks.

