Today, MLCommons announced new results from its MLPerf Inference v4.0 benchmark suite with machine learning (ML) system performance benchmarking. To view the results for MLPerf Inference v4.0 visit the Datacenter and Edge results pages.
The MLPerf eInference benchmark suite, covering data center and edge systems, is designed to measure how quickly hardware systems can run AI and ML models in a variety of deployment scenarios. In order to keep pace with today’s ever-changing generative AI landscape, the working group created a new task force to determine which of these models should be added to the v4.0 version of the benchmark. This task force analyzed factors including model licenses, ease of use and deployment, and accuracy in their decision-making process.
MLCommons said it decided to include two new benchmarks to the suite: the Llama 2 70B model was chosen to represent the “larger” LLMs with 70 billion parameters, while Stable Diffusion XL was selected to represent text-to-image generative AI models.
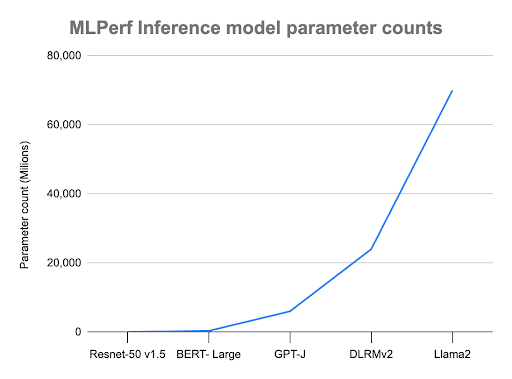
Llama 2 70B is an order of magnitude larger than the GPT-J model introduced in MLPerf Inference v3.1 and correspondingly more accurate. One of the reasons it was selected for inclusion in the MLPerf Inference v4.0 release is that this larger model size requires a different class of hardware than smaller LLMs, which provides a great benchmark for higher-end systems. We are thrilled to collaborate with Meta to bring Llama 2 70B to the MLPerf Inference v4.0 benchmark suite. More information about the selection of Llama 2 is in this post.
“Generative AI use-cases are front and center in our v4.0 submission round,” said Mitchelle Rasquinha, co-chair of the MLPerf Inference working group. “In terms of model parameters, Llama 2 is a dramatic increase to the models in the inference suite. Dedicated task-forces worked around the clock to set up the benchmarks and both models received competitive submissions. Congratulations to all!”
 For the second new generative AI benchmark, the task force chose Stability AI’s Stable Diffusion XL, with 2.6 billion parameters. This popular model is used to create compelling images through a text-based prompt. By generating a high number of images, the benchmark is able to calculate metrics such as latency and throughput to understand overall performance.
For the second new generative AI benchmark, the task force chose Stability AI’s Stable Diffusion XL, with 2.6 billion parameters. This popular model is used to create compelling images through a text-based prompt. By generating a high number of images, the benchmark is able to calculate metrics such as latency and throughput to understand overall performance.
“The v4.0 release of MLPerf Inference represents a full embrace of generative AI within the benchmark suite,” said Miro Hodak, MLPerf Inference co-chair. “A full third of the benchmarks are generative AI workloads: including a small and a large LLM and a text-to-image generator, ensuring that MLPerf Inference benchmark suite captures the current state of the art.”
MLPerf Inference v4.0 includes over 8500 performance results and 900 Power results from 23 submitting organizations, including: ASUSTeK, Azure, Broadcom, Cisco, CTuning, Dell, Fujitsu, Giga Computing, Google, Hewlett Packard Enterprise, Intel, Intel Habana Labs, Juniper Networks, Krai, Lenovo, NVIDIA, Oracle, Qualcomm Technologies, Inc., Quanta Cloud Technology, Red Hat, Supermicro, SiMa, and Wiwynn.
Four firms–Dell, Fujitsu, NVIDIA, and Qualcomm Technologies, Inc.–submitted data center-focused power numbers for MLPerf Inference v.4.0. The power tests require power-consumption measurements to be captured while the MLPerf Inference benchmarks are running, and the ensuing results indicate the power-efficient performance of the systems tested. The latest submissions demonstrate continued progress in efficient AI acceleration.
“Submitting to MLPerf is quite challenging and a real accomplishment”, said David Kanter, executive director of MLCommons. “Due to the complex nature of machine-learning workloads, each submitter must ensure that both their hardware and software stacks are capable, stable, and performant for running these types of ML workloads. This is a considerable undertaking. In that spirit, we celebrate the hard work and dedication of Juniper Networks, Red Hat, and Wiwynn, who are all first-time submitters for the MLPerf Inference benchmark.”
