
In this special feature, our “Performance Guru” Bill D’Amico looks at the NVLink technology introduced by Nvidia last week at the GPU Technology Conference.

Bill D’Amico, insideHPC Performance Guru
As described here on insideHPC, NVLink promises 5-12X faster memory transfers that will allow some codes significant speedups. Coupled with the large and very high bandwidth stacked memory of the Pascal GPU, NVLink has game changing potential.
In this post, I’ll be looking at NVLink from an engineering point of view. There have been several articles posted on NVLink already that speak to the potential value of a high bandwidth and low power interconnect between GPUs and some CPUs, but what needs to happen to realize this value?
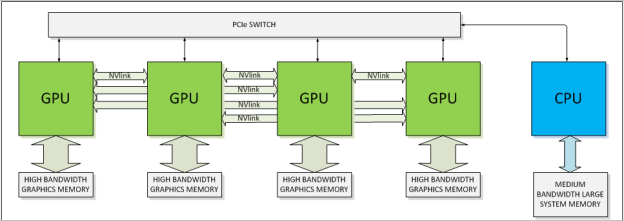
Specific benefits for the Pascal GPU and NVLink:
- Lower power GPU processing units due to architectural and process improvements
- Internal GPU memory bandwidth increase of 2X-5X (primarily due to a wider data path and closer memory cells enabled by stacked memory)
- Smaller form factor cards, enabling up to 8 GPU cards per system
- Data transfer speeds of 5X-16x over PCIe3 using NVLink
NVLink will only operate within a single chassis – clustering GPU accelerated machines will not be able to take advantage of the increased bandwidth using NVLink. It seems likely that interconnect vendors like Mellanox will produce interface cards that enable IB-NVLink transfers so communication between NVLink enabled nodes can bypass the PCI bottleneck.
Unified Memory
I spoke with Ian Buck of Nvidia about NVLink during the GPU Technology Conference and he pointed me to an upcoming GTC talk by Mark Harris. Mark gave a good talk about Future Directions for CUDA and touted the benefits to programmers of a Unified Memory Model – writing code that has GPU acceleration enabled will be easier because programmers won’t have to explicitly program memory buffer transfers. He also spoke about making CUDA accessible to a broader range of programming languages and new work on providing libraries to take full advantage of CUDA acceleration. However the talk doesn’t give any pointers to memory model specifications that hardware vendors will need to in order to use unified memory, nor how the new interconnect plans to implement unified memory. This may be due to the work still being in the very early stages.
Unified memory for GPU and CPU is hard to implement. Structures describing memory pages need to cause memory transfers depending on physical location of a page of memory – if CPU needs a page that is currently in GPU memory that needs to cause a trap and a transfer (over either PCIe or later NVLink) and vice versa for GPU needing a page from CPU memory. This can be simplified by specifying physical address ranges for devices (which is part of the specifications for the memory model) , but there is still a need to update Translation Lookaside Buffers and cache tables. These functions are best done using specialized hardware in the respective devices – Memory Management Units in the CPU, IOMMU in peripheral devices.
For NVLink to have its highest value it must function properly with unified memory. That means that the Memory Management Units in the CPUs have to be aware of NVLink DMA operations and update appropriate VM structures. The operating system needs to know when memory pages have been altered via NVLink DMA – and this can’t be solely the responsibility of the drivers. Tool developers also need to know details so that MPI or other communications protocols can make use of the new interconnect.
NVLink for the Power Architecture
Nvidia is working with IBM to get this into the Power architecture MMU, and presumably will be putting similar work into NVidia ARM CPUs. For other vendors to do the same the detailed memory model specifications and some compliance testing material will need to be released – preferably under licensing that does not discourage other vendors. These specifications will also need to be shared with developers of both tools and operating systems. If this doesn’t happen then the full benefits made possible by NVLink will be limited to a smaller ecosystem of Power and (some) ARM machines. Codes currently running on BlueGene architectures should benefit when Pascall and NVLink launches.
The HPC community moved to commodity x86 processors en masse, and in recent years has added GPU acceleration to the mix. This has come at significant cost in porting codes from older proprietary processors. The value in having x86 processors able to function in fully unified memory systems that utilize NVLink as part of their memory system is clear – higher bandwidth memory access without the pain of porting to a new CPU architecture.
Will NVidia help make this happen? Readers should watch for licensing terms when detailed specifications are published. If the underlying technology is licensed with low cost royalties we may see not only x86 CPU able to run efficiently with NVLink enabled GPUs, but also NVLink available as an high bandwidth link between next generation Xeon Phi coprocessors. If not we’ll see a new fragmentation of the HPC marketplace and a continuing need for developers to target tools at multiple platforms.

