
Sponsored Post

Rob Farber
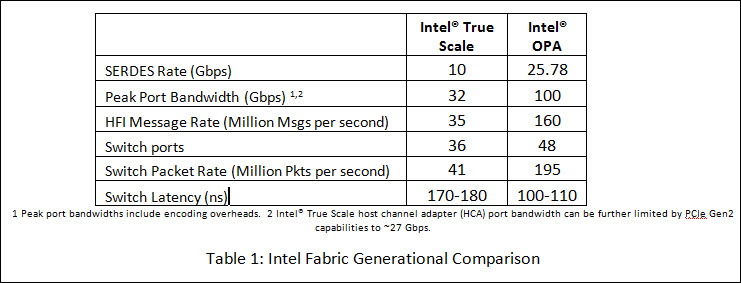
The next generation of network technology, Intel® Omni-Path Architecture, is backed by Intel’s pervasive Enterprise and HPC market X86 processor presence. The latest innovations that the technology brings to the table are detailed in the Intel® Omni-Path Architecture: Enabling Scalable, High Performance Fabrics technical white paper released last week at IEEE Hot Interconnects. The compelling Omni-Path specs include: (a) a 4.6x improvement in small message throughput over the previous generation InfiniBand fabric technology, (b) a whopping 70ns decrease in switch latency (think how all those latencies add up across all the switches in a big network), (c) a single ASIC that can deliver 50 GB/s of dual-channel bidirectional bandwidth, or 12.5GB/s single channel unidirectional bandwidth. In short, Omni-Path delivers all this and more as an integrated component inside the processor package or via other form factors like PCIe cards or custom mezzanine cards.
The combination of technical information and Intel’s significant commitment to Intel® Omni-Path Architecture makes this whitepaper a “must read”. Backed by years of design and Intel’s extensive HPC and enterprise experience, Omni-Path should certainly be considered for future system designs. By reading Intel® Omni-Path Architecture: Enabling Scalable, High Performance Fabrics you will better understand the performance enhancements that the next generation fabric will bring to network connectivity.
Very briefly, the Intel Omni-Path Architecture (Intel® OPA) whitepaper goes through the multitude of improvements that Intel OPA technology provides to the HPC community. In particular, HPC readers will appreciate how collective operations can be optimized based on message size, collective communicator size and topology using the point-to-point send and receive primitives. MPI scaling has been increased to support hundreds of thousands of processor cores plus Intel OPA opens the door via a number of APIs (specifically MPI, Performance Scaled Messaging and Verbs) through the OpenFabric Alliance OFED stack. This provides for compatibility of applications written to the OFED stack on InfiniBand and Intel OPA. Similarly, the HPC community will be happy to read about a well thought out set of QoS, reliability, security and congestion management protocols that are a boon to multi-use, virtualized, and large scale environments. These revolutionary features include:
- Traffic Flow Optimization: periodically makes priority decisions so important MPI files don’t get blocked by low priority storage files. High priority jobs won’t be delayed and run-to-run inconsistencies will be minimized.
- Dynamic Lane Scaling: guarantees that a workload will gracefully continue to completion even if one or more lanes of a 4x link fail, rather than shutting down the entire link which was the case with InfiniBand.
- Packet Integrity Protection: reduces latency by catching and correcting all single/multi-bit errors in the fabric, so end-to-end retries may only happen once every 5-10 years in typical use with an additional CRC option that increases the timeframe even further.
Those features are great because together they help deliver enhanced performance through higher MPI rates, lower latency and higher bandwidth to support the next generation of datacenters.
Network designers and specialists will appreciate how hotspots are avoided inside the Omni-Path fabric, and how the fabric itself is designed to take advantage of locality between processing, cache, memory, and the communication infrastructure. While still new, the next-generation Omni-Path design provides enhancements over previous high performance fabric technologies. This means that Intel OPA is the next generation interconnect without the risk associated with brand new technologies.
Higher network density, in combination with Omni-Path connectivity which will be integrated inside the processor package—of which the future Intel® Xeon Phi™ processor known as Knights Landing is the first instantiation—brings many benefits. The integrated HFI provides additional cost structure savings, reliability and performance gains. Given that many HPC applications are network latency bound, even the smallest reduction in latency can result in significant application performance improvements. With Intel OPA, designers now have the ability to build smaller, more closely integrated clusters (a benefit in terms of cabling and the latency incurred by routers and other electronics required to move the network data). Alternatively, designers can add an extra network card (when space permits) to double network bandwidth via bonded interfaces or potentially provide multiple, application-specific optimized network topologies within the same data center or supercomputer.
Even though the authors note that “A full treatment of the [Omni-Path] software ecosystem is beyond the scope of this paper”, this whitepaper is well worth the read. Further disclosures about the product and ecosystem are sure to come as Intel has announced that product availability is scheduled for 4th quarter of this year.
Download Intel® Omni-Path Architecture: Enabling Scalable, High Performance Fabrics
This article was written by Rob Farber, editor of techENABLEMENT.com.

the link to the whitepaper is broken.
Sorry you are having trouble. The Intel whitepaper requires registration: https://plan.seek.intel.com/ThankYouPage-IntelFabricsWebinarSeries-Omni-PathWhitePaper-3850
thanks!
aperantly a browser plugin prevented the page to load.
opening it in a new private browsing window worked