
Douglas Wade, Department of Energy National Nuclear Security Administration
In this video, Douglas P. Wade from NNSA describes the computational challenges the agency faces in the stewardship of the nation’s nuclear stockpile. As the Acting Director of the NNSA Office of Advanced Simulation and Computing, Wade looks ahead to future systems on the road to exascale computing.
Transcript:
As mentioned, I am currently heading the Office of Advanced Simulation and Computing in the National Nuclear Security Agency. Our mission is basically to provide the simulation capabilities necessary to support the U.S. nuclear deterrent. That includes both the stockpiles that exist today and to prepare for what’s coming in the future. In order to do so, we need to also provide cutting edge computer capabilities, simulation capabilities, and facilities for our three laboratories – Los Alamos, Sandia, and Livermore.
Let’s see. Basically, stockpile stewardship depends on the simulation capabilities and the fact, from my point of view, the only purpose the Stockpile Stewardship Program exists is to provide the information necessary to support the codes because the codes is the repository of all our understanding of nuclear weapon science. They basically allow us to not conduct underground nuclear tests anymore to assure the continued safety and security of the stockpile. However, to do this, some of the most complex codes ever devised are needed – large multiphysics codes that each of them run around a million plus lines and have been developed over a couple of decades and at very great cost.
 We are seeing problems in the immediate future. We’re already starting to get hit with these problems because the changes that the computer industry is taking. Basically, our computer architectures have gone through a number of regimes over the– since the 1960s, starting with the vector machines. I first started programming at Cray-1 too long ago [chuckles], like early 1980s. That gave way to what we’ve been into for a fairly long time now – the distributed memory – basically using commercial off-the-shelf technology in large ranges.
We are seeing problems in the immediate future. We’re already starting to get hit with these problems because the changes that the computer industry is taking. Basically, our computer architectures have gone through a number of regimes over the– since the 1960s, starting with the vector machines. I first started programming at Cray-1 too long ago [chuckles], like early 1980s. That gave way to what we’ve been into for a fairly long time now – the distributed memory – basically using commercial off-the-shelf technology in large ranges.
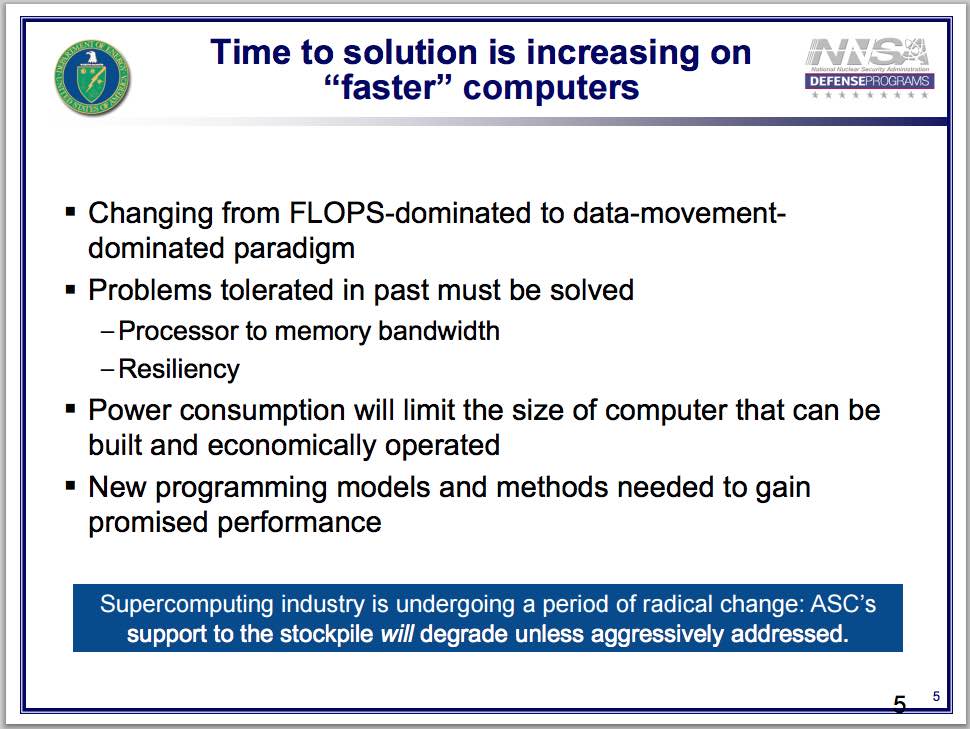
Right now we’re moving into a regime which we haven’t been before. That’s the direction the computer industry is going. We’re coming to an end of the performance you can get out of the existing technology, and it has been made up for a long while now to go to increasing levels of parallelism. And that’s about to explode even more so than it has been to date.
The net result is, for us, we get a faster computer and our simulations run slower, and that’s going to continue. That’s because when we wrote these codes we were in an era – which we’ve been into up until almost now – where CPU time was very precious and memory was– we had plenty of memory available. We wrote codes that took advantage of that so that they run efficiently. We’re entering an era where just the reverse is true. Flops, the mini core, GPUs – we have all the flops we need right now. But it’s the memory, really the data movement, that’s restricting us. As a result, as I said, we’re already on the highest level – highest tier of computing. We’ve got the Sequoia Machine. We’re seeing our codes run more slowly than they did on the previous one. If not mitigated, that’s going to require– it was going to see us at least stagnate over the coming– looking at between now and when excess scale would be online, a 600% loss in performance potentially.
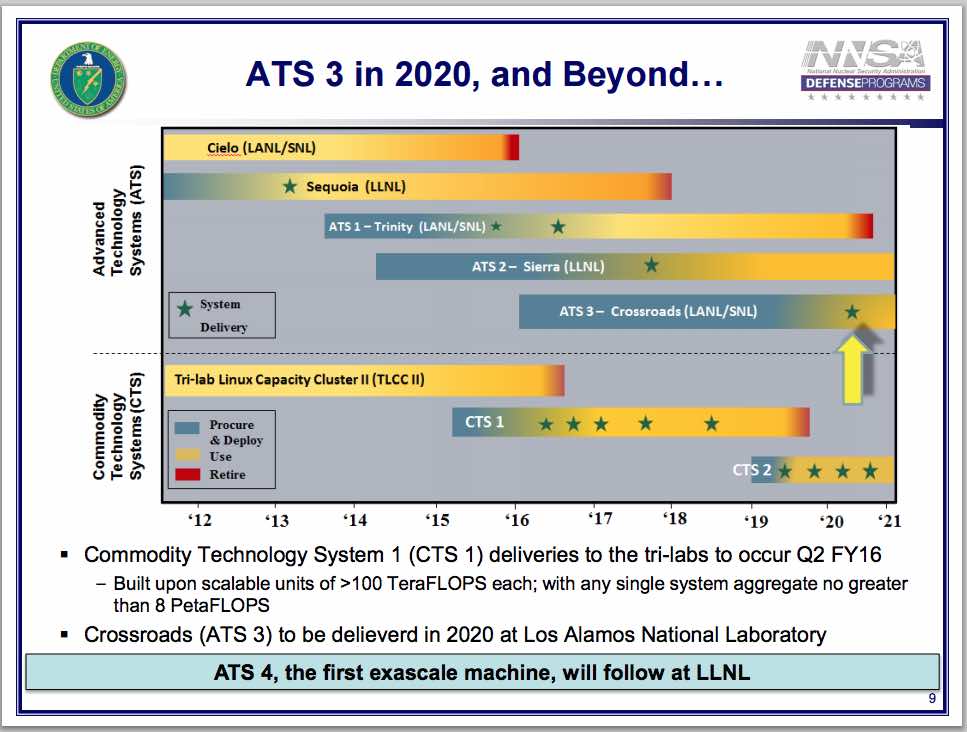
Now we are taking a number of steps to mitigate this. There’s nothing inherent in this except for our code architectures, but basically we’re going to have to rewrite or evolve our current codes- which are again very difficult to build and maintain in the first place – to take advantage of the new structures. And we’re also looking at writing from scratch new codes to design from the bottom up to take advantage of the architectures. An example is in the past we stayed away from higher order schemes because solving a lot of the physics problems involved because they took up a lot of CPU power. Instead we just heavily zoned in on the problem. In the future, we’ll probably go with reverse. We’re looking at a lot of high order schemes. And the machines that are going to drive us this way, a number of them that we have coming at us, Trinity is on the floor now at Los Alamos being checked out for the first phase. That machine actually is going to come in in two phases. The first one looks pretty much like the existing architectures with a few improvements, such as burst buffers. But the second phase will be using the Knights Landing many core chips, and that’s going to cause us to again take a difference in how we program these things to take advantage of them.
 As Steve mentioned, we are very tightly joined with the Office of Science computers. They’ve got the equivalent machine going in at Lawrence Berkeley. After the Trinity machine, NNSA will be citing a replacement for the current Sequoia machine at Livermore, and this one will be called Sierra. And as you can see, we’re looking at something in the 150 petaflop class. This going to be a new CPU architecture for us. It’s based on the idea empower series, and it’s also going to have GPUs, which is new for the NNSA, although Titan has GPUs. But again, different architectures. Beyond that, we’ve just recently approved an initial concept development for the follow on machine.
As Steve mentioned, we are very tightly joined with the Office of Science computers. They’ve got the equivalent machine going in at Lawrence Berkeley. After the Trinity machine, NNSA will be citing a replacement for the current Sequoia machine at Livermore, and this one will be called Sierra. And as you can see, we’re looking at something in the 150 petaflop class. This going to be a new CPU architecture for us. It’s based on the idea empower series, and it’s also going to have GPUs, which is new for the NNSA, although Titan has GPUs. But again, different architectures. Beyond that, we’ve just recently approved an initial concept development for the follow on machine.
 There are ATS3, Advanced Technology System, to go in at Los Alamos. That machine will be named Crossroads, and that will probably be the last machine we have before we get to exascale — ATS4 will be the first exascale machine, we hope. Exascale itself is coming. It’s coming in the early 2020s. Not sure, our CMOS technology – which we’ve relied on for decades now – is coming to an end, at least for getting additional performance out of it. We’re beginning to look at other technologies that may someday supplant things like quantum computing, neuromorphic. We’re at the very earliest stages, but these are technologies that y’all will probably have to deal with during your careers, or a decade or more away. There’s also other non-CMOS technologies that may come in and some of you will help pioneer all of that. You people here are the source of the future. You are the future. You’re going to be the ones that figure out how to adapt to meet these challenges of new ways of writing code, new algorithms that can be implemented to solve a variety of problems.
There are ATS3, Advanced Technology System, to go in at Los Alamos. That machine will be named Crossroads, and that will probably be the last machine we have before we get to exascale — ATS4 will be the first exascale machine, we hope. Exascale itself is coming. It’s coming in the early 2020s. Not sure, our CMOS technology – which we’ve relied on for decades now – is coming to an end, at least for getting additional performance out of it. We’re beginning to look at other technologies that may someday supplant things like quantum computing, neuromorphic. We’re at the very earliest stages, but these are technologies that y’all will probably have to deal with during your careers, or a decade or more away. There’s also other non-CMOS technologies that may come in and some of you will help pioneer all of that. You people here are the source of the future. You are the future. You’re going to be the ones that figure out how to adapt to meet these challenges of new ways of writing code, new algorithms that can be implemented to solve a variety of problems.
With that, we have no choice but to go where we’re going. We’re not doing exascale for the sake of doing exascale. On both sides, on a national security side, we have problems right now that we know how to solve, but we can’t, so we’re going to continue to pursue these computers. We recently shut down a calculation that we ran on a petaflop class machine for almost a year just because the machine wasn’t up to it. We will restart that on Trinity and see if we can solve this. We know the way to solve the problem. We just don’t have the computational power. We will continue to push the state-of-the-art until we can answer the questions we need, and again it’s going to depend on people in this room to help us get there.
Download the Slides (PDF) * Sign up for our insideHPC Newsletter

