
In this special guest feature, James Reinders looks at Intel Xeon Phi processors from a programmer’s perspective.
 How does a programmer think of Intel Xeon Phi processors? In this brief article, I will convey how I, as a programmer, think of them. In subsequent articles, I will dive a bit more into details of various programming modes, and techniques employed for some key applications. In this article, I will endeavor to not stray into deep details – but rather offer an approachable perspective on how to think about programming for Intel Xeon Phi processors. For a detailed examination of Intel Xeon Phi processor programming (632 pages), I recommend our book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition. However, in these articles, I offer brief summaries of what we cover in the book with the advantage of being able to convey the intent very concisely while leaving the details and nuances to our book and our companion website (where example code resides).
How does a programmer think of Intel Xeon Phi processors? In this brief article, I will convey how I, as a programmer, think of them. In subsequent articles, I will dive a bit more into details of various programming modes, and techniques employed for some key applications. In this article, I will endeavor to not stray into deep details – but rather offer an approachable perspective on how to think about programming for Intel Xeon Phi processors. For a detailed examination of Intel Xeon Phi processor programming (632 pages), I recommend our book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition. However, in these articles, I offer brief summaries of what we cover in the book with the advantage of being able to convey the intent very concisely while leaving the details and nuances to our book and our companion website (where example code resides).
Intel Xeon Phi processors are marketed primarily as a supercomputer building block, because of its combination of extreme performance and energy efficiency. However, technically it could be designed into any server or PC as the CPU and run any operating system that runs on x86 (you’d want to use modern x86 operating systems are that are ready to fully use so many cores!).
Key things about Intel Xeon Phi processor:
- It is a fully compatible x86 processor with full 64 bit capabilities.
- It has more x86 cores than any processor before it; Intel Xeon Phi processors have up to 72 cores (some product versions have fewer cores). The physical cores support four threads per core, therefore the processors offer up to 288 logical cores.
- What was formerly known as “Knights Landing” is known officially by Intel as the Intel® Xeon Phi™ product family.
Compatibility a unique advantage?
Intel’s pitch for Intel Xeon Phi processors has two aspects: compatibility and extreme performance. Competitors will debate who has the top performance, and the ease or difficulty of obtaining that performance. But, Intel has a unique claim on compatibility with an architecture (x86) that powers most PCs and servers in the world.
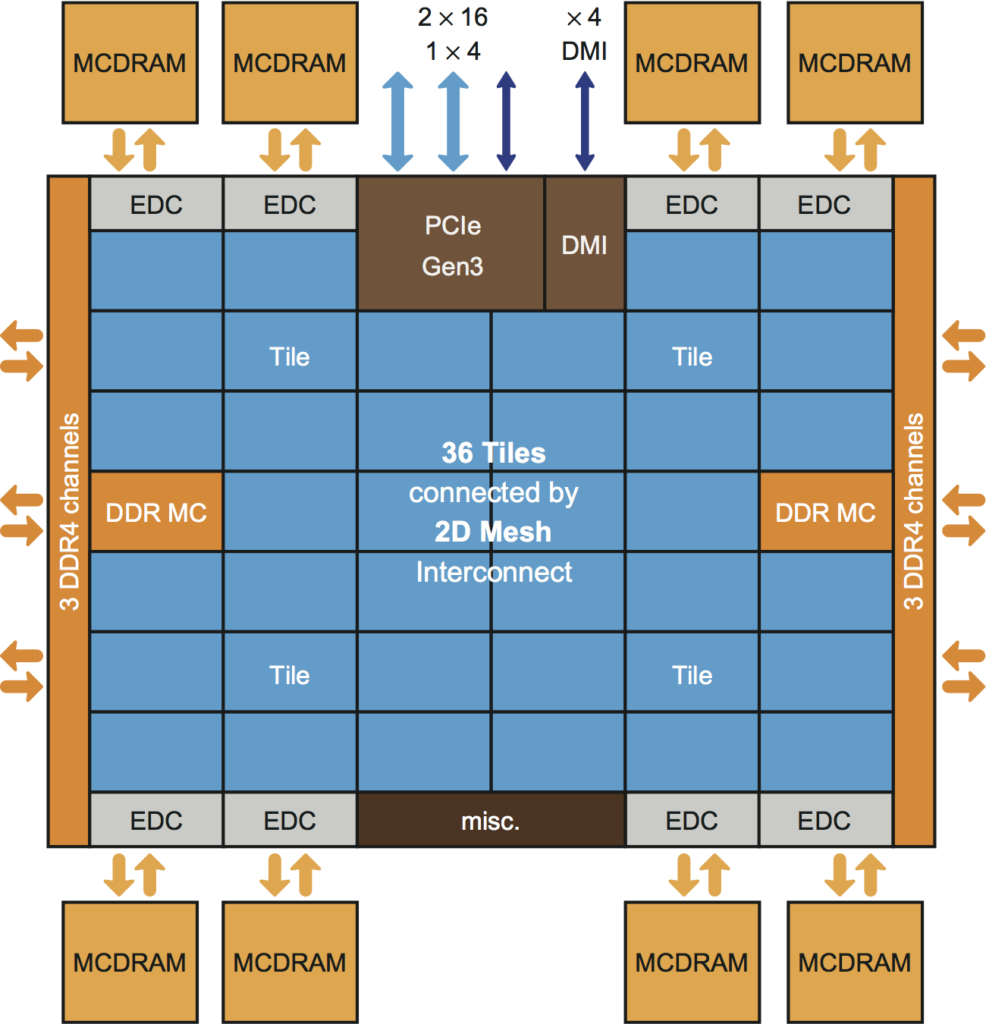
Intel Xeon Phi processor architecture – up to 72 x86 cores
Why know more? Performance!
There are many more things to talk about with Intel Xeon Phi processors, but frankly a programmer only needs to know more details if performance is important. Of course, supercomputer programmers care a great deal about performance so it would be odd to not discuss performance considerations when discussing Intel Xeon Phi processor.
Performance for Vectors
Processors compute most effectively on streams of data (vectors) by utilizing SIMD instructions (vector instructions). Intel first added SIMD instructions to the x86 instruction set with MMX instructions nearly two decades ago. Since then, additional instructions expanded capabilities to 128-bit SIMD with SSE, SSE2, SSE3, SSSE3, SSE4.1 and SSE4.2. More recently, AVX and AVX2 instructions expanded SIMD width to 256 bits. Now, Intel offers AVX-512 instructions which offer 512 bit SIMD instructions. Intel Xeon Phi processor supports all these SIMD formats, with the highest performance coming from AVX-512. AVX-512 instructions operate on 512 bits of data at a time – which means 16 single precision floating point operations, or 8 double precision operations, at a time. This yields roughly twice the maximum performance over AVX/AVX2 and four times that of various SSE instruction sets.
Therefore, a key to performance with the processors is using AVX-512 instructions. Vectorization is a familiar optimization needed for top performance on any processor. Unlike GPUs, the concept of vectorization is very distinct from that of multithreading. This is a two edged sword – offering much more flexibility, but at the expense of having two things to optimize rather than one. The advanced capabilities of AVX-512 do help compilers and programmers vectorize more easily than any prior SIMD instruction set – applications which have been optimized for vectorization previously do stand an excellent chance of “just compiling well”. However, vectorization remains a potentially non-trivial optimization when maximum performance is desired. Vectorization is important enough that we dedicated four chapters in our book to various aspects of vectorization as well as showing real world examples in the book. In a future article, I will discuss vectorization from the perspectives of each of our four vectorization chapters.
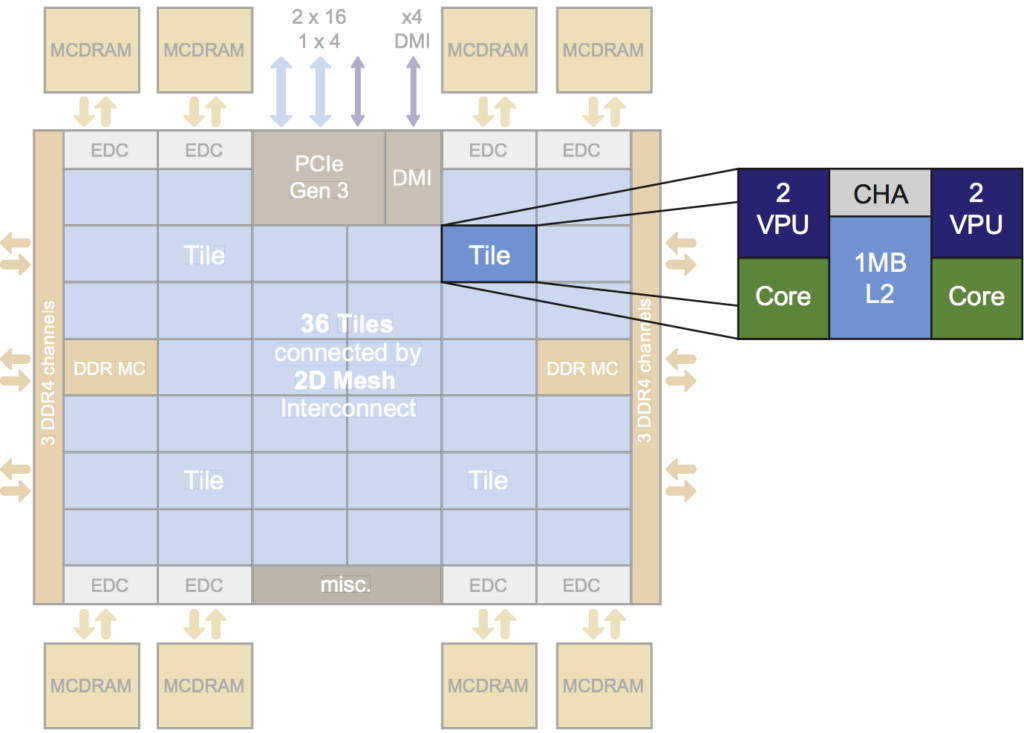
An Intel Xeon Phi processor is organized in pairs of x86 cores called “tiles”. Each tile has local access to a portion of the global L2 cache. Each core has two vector processing units. The “CHA” (Caching/Home Agent) connects these tiles to other tiles in the processor.
Performance for “Lots of Cores” – aka “Feed the Beast”
Every new machine that I’ve worked on has been faster than anything that preceded it. As a result, we always wonder “how will we feed the beast?” Intel Xeon Phi processors beg the same question, and the architects of the processors offer some special features to help. This is because the highest performance does not happen if you cannot get data to and from the compute engines.
I like to think of Intel Xeon Phi processors as a system (a “cluster” in particular) on a chip. I believe that puts everything into perspective – including the special “mode” features offered on the processors for performance.
There are two design issues that loom large with a cluster design such as Intel Xeon Phi processors, which the architects decided to support via unprecedented configuration capabilities. These are MCDRAM and cluster modes. While both are interesting, if you only study one of them, MCDRAM modes is the one to study. I will discuss MCDRAM modes here since they may affect decisions about programming; I will revisit cluster modes in a future article as a tuning knob for MPI programmers when running programs.
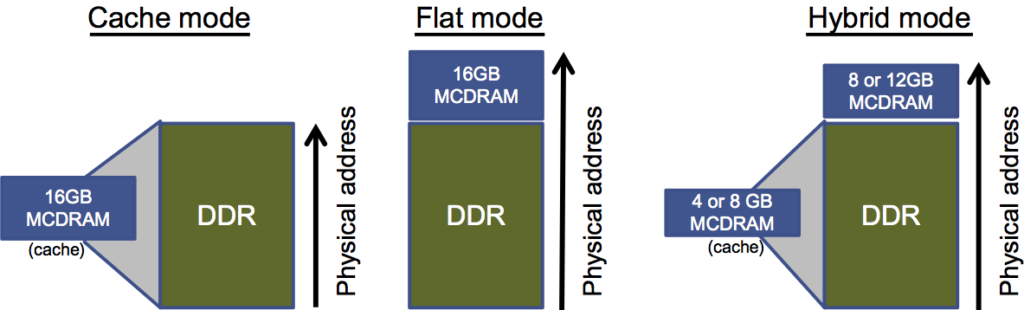
Intel Xeon Phi processors can have a 16M memory included in the package called “MCDRAM.” The MCDRAM can be used as a cache (effectively an L3 cache), as a high bandwidth memory (scratch memory), or some of both. These are called “cache”, “flat” and “hybrid” modes, respectively.
MCDRAM modes
MCDRAM is an exciting design (CPU-L1-L2-MCDRAM-memory) which offers higher performance than a simpler design (CPU-L1-L2-memory) would give. This performance boost is present in the default MCDRAM “cache” mode, but in some circumstances programmers can do even better with careful use of “flat” mode. These “modes” are running modes for the processor set at boot time based on BIOS settings.
The MCDRAM offers high bandwidth memory (16M). In most system designs using Intel Xeon Phi processors, there will be additional main memory (DDR). The MCDRAM is not faster than DDR. It offers higher bandwidth. Therefore, use of MCDRAM is critical for computations that are reading/writing a lot of data simultaneously. The default is for MCDRAM to operate as a cache, and it turns out this is very hard to beat. However, for clever programmers or algorithms which are not “cache friendly”– using the MCDRAM, in “flat” mode, under program control (instead of letting the processor manage it automatically as a cache) can be an advantage. We can also split the MCDRAM into some cache and some “flat” – this is called “hybrid” mode.
Programs should be tuned for vectorization first (with MCDRAM in cache mode). A big motivation in giving this advice is knowing that memory accesses can change when vectorizing code – so this order of development can avoid tuning memory for the wrong access patterns.
If direct management of MCDRAM seems like a good idea, then we will compare results that we get using “flat” mode with that of “cache” mode. I’ve seen more than a few excellent programmers frustrated by how good “cache” mode is. The key to the challenge is that the processors are excellent at using the whole cache. When we choose to use “flat” mode, we really need to use all the memory to our advantage. Any memory that we leave idle simply makes it easier for the “cache” mode to out perform our implementation.
I will dive into “flat” mode programming in more detail in a follow-up article. At a high level, there are three ways to take advantage of MCDRAM in “flat” mode. One method is to have all memory requests mapped to MCDRAM using the numactl utility, another is to intercept memory requests and map some of them (based on size) to MCDRAM, or we can exercise full control using special memory allocators or compiler controls on a variable by variable or allocation by allocation basis.
Each method is easy enough, and only the last choice involves code changes. I believe high bandwidth memory will become a common feature in system designs in the future, so beneficial code changes are likely to be useful beyond the Intel Xeon Phi processor. Code changes are straightforward – we simply change “malloc” calls to “hbw” malloc calls (a different function), or we annotate Fortran ALLOCATE keywords to ask for high bandwidth memory.
Carefully done, I’ve seen code changes to use MCDRAM directly give some advantage. However, I’ve also seen many programmers frustrated by how good “cache” mode really is for their programs. The architects really did an excellent job with cache mode. Regardless of your circumstances, vectorize first!
Summary

All Figures are adopted from the book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition, used with permission per lotsofcores.com
Intel Xeon Phi processors are remarkable x86 devices – featuring up to 72 x86 cores, and including numerous design features to allow very high performance usage as building blocks for the world’s most powerful supercomputers. For programmers, the most important high performance features to understand are vector processing (AVX-512), MCDRAM modes and cluster modes. In future articles, I will offer a deeper look at particular things that I touched on this in this piece.
James Reinders likes fast computers and the software tools to make them speedy. James recently concluded a 10,001 day career at Intel where he contributed to projects including the world’s first TeraFLOPS supercomputer (ASCI Red), compilers and architecture work for a number of Intel processors and parallel systems. James has been the driving force behind books on Intel VTune (2005), Intel Threading Building Blocks (2007), Structured Parallel Programming (2012), Intel Xeon Phi coprocessor programming (2013), Multithreading for Visual Effects (2014), High Performance Parallelism Pearls Volume One (2014) and Volume Two (2015), and Intel Xeon Phi processor (2016). James resides in Oregon, where he continues to enjoy parallelism and teaching.

