
In this special guest feature, James Reinders describes how programmers can exploit memory modes in the Intel Xeon Phi processor.

James Reinders, parallel programming enthusiast
Intel Xeon Phi processors have two features that I believe we will see in more and more designs for HPC systems in the future: high bandwidth memory, and options for subdividing the many cores into regions.
Previously, I gave an overview in “Intel Xeon Phi processor Programming in a Nutshell” of how to approach the Intel® Xeon Phi™ processor often referred to as Knights Landing.
In this article, I will discuss one of the “mode” options that Intel Xeon Phi processors have to offer unprecedented configurability: memory modes. For programmers, this is the key option to really study because it may inspire programming changes. In my next article, I’ll tackle the other mode option (cluster modes).
The memory modes allow the MCDRAM to be used as either a high bandwidth cache or a high bandwidth memory, or a little of each.
MCDRAM exists for bandwidth
Computationally intense programs are often bandwidth limited. Of course, the highest performance does not happen if we cannot get data to and from the compute engines. Intel Xeon Phi processors include an “on package” MCDRAM to increase bandwidth available to an application at the same level in the memory hierarchy as the main (DDR) memory, but with higher bandwidth.
Memory modes (see table) allow the processor memory configurations to be determined at boot time. MCDRAM can be viewed as a high bandwidth alternative to the regular memory (DDR). In fact, a system does not need to have regular memory at all. In systems with DDR memory, the MCDRAM can serve as a high bandwidth cache for DDR memory.
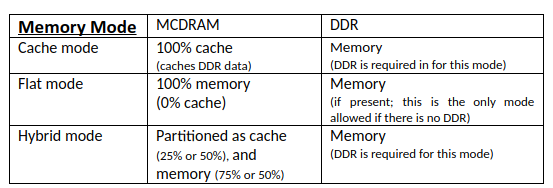
MCDRAM stands for “Multichannel” DRAM… the multichannel being the key to more bandwidth. More channels to the DRAM means more simultaneous accesses are possible (more bandwidth).
MCDRAM is “on package” which means it is inside the same package that we would see or hold in our hand, but it is on a separate piece of silicon (die). In general, separate dies allow more transistors than would fit on a single die (so the processor can have more cores and the memory can be larger), and it allows a processor die to use fabrication tuned for general logic while a memory chip is tuned for memory. Otherwise, “on package” vs. a single die end up functioning in a technically equivalent manner.
High bandwidth does not mean faster. Individual access times to MCDRAM versus DDR are virtually identical in performance. The “faster” only comes if more simultaneous cache lines are needed. The MCDRAM can provide multiple responses at once, whereas the DDR will need to do them one after the other. This is effectively faster, but only because of additional bandwidth.
Tune for Parallelism before playing with Memory Modes
When I teach programming for Intel Xeon Phi processors, everyone is anxious to learn about all the things that are unique to this processor. I have found it incredibly to be important to stress that first and foremost, Intel Xeon Phi is a parallel processor. And, it is pretty darn good at being a parallel processor even with its default settings! That means that our first and most important task is to have an effective parallel program. In fact, I emphasize this as a rule for programming Knights Landing.
First rule of Intel Xeon Phi processor programming: Initially most applications have far more to gain from fine tuning for parallelism than from fiddling with memory and cluster modes.
For instance, programs should be tuned for vectorization first (with MCDRAM in cache mode). I say this knowing that memory access patterns can change when vectorizing code. This means that the order of development can avoid tuning memory (trying different modes) for the wrong access patterns.
In this article, I do want to introduce and explain memory modes from a programmer’s point of view. Our book offers deeper dives in Chapters 4 and 6 for those inclined to understand the underlying hardware in great detail. I will focus on the key interfaces for programmers to build a firm foundation for using memory and cluster modes.
MCDRAM cache mode: default, easy, and effective
If direct management of MCDRAM seems like a good idea (using the flat memory mode), then we should compare results that we get using “flat” mode with that of “cache” mode. I’ve seen more than a few excellent programmers frustrated by how good “cache” mode is. The key to the challenge is that the processors are excellent at using the whole cache. When we choose to use “flat” mode, we really need to use all the memory to our advantage. Any memory that we leave idle simply makes it easier for the “cache” mode to outperform our implementation.
Assuming some or all of MCDRAM is configured as cache, there is nothing specific that must be done in a program to use the cache. Of course, the usual cache optimizations apply that would apply for other levels of cache or systems with L3 caches.
Ultimately, this means that all our focus on “what’s new” for memory modes is really about flat mode, or the flat part when running in hybrid mode.
MCDRAM as memory using flat or hybrid mode
There are three ways to take advantage of MCDRAM in “flat” mode. One method is to have all memory requests mapped to MCDRAM using the numactl utility, another is to intercept memory requests and map some of them (based on size) to MCDRAM, or we can exercise full control using special memory allocators or compiler controls on a variable by variable, or allocation by allocation, basis. “numactl” is an abbreviation for “NUMA control.” NUMA is an acronym for Non-Uniform Memory Access, in this case specifically a reference to the fact that accessing the main memory (DDR) and MCDRAM memory have different characteristics and are therefore not uniform in behavior from the standpoint of an application using the memory. In a future article, when I discuss cluster modes there are additional opportunities for NUMA behavior even within DDR or MCDRAM when using SNC-2 or SNC-4 cluster modes. The key here is that the numactl utility helps us control how the operating system maps the memory needs of an application onto the various memories at our disposal.

numactl
Intel purposefully set up the MCDRAM memories, via tables produced in the BIOS, in such a way that the BIOS and the operating systems do not see them as the most desirable memories. If they did, the operating system kernel would be sitting in MCDRAM before we started our application. Therefore, when our programs runs we can use numactl to switch to preferring MCDRAM.
If you do not have numactl on your system – you need only install it:

The numactl utility has many options, but the simplest simply says “use MCDRAM” for the data allocations of this program:
![]()
This command has data (including the stack) come from NUMA node 1. Understanding which NUMA nodes map to which MCDRAM requires understanding cluster modes, which I will discuss in a future blog. Assuming the cluster mode remains the default (quadrant), then the processor is running as a single collection of processors and the only “NUMA” going on is DDR vs. MCDRAM. Assuming we have DDR installed, then DDR will be NUMA node 0 and the MCDRAM will be NUMA node 1 assuming we have memory mode set to something other than cache. The command “numactl –H” will dump out information about NUMA nodes on your particular system.
Preferring (-p) vs. requiring (-m)
A big question when using MCDRAM is whether an allocation must use MCDRAM (numactl -m) or just prefer it (numactl –p). Generally, I find programmers want to require it and then debug their program if they have not precisely planned the layout perfectly. This seems like a good idea, but there are two complications. First, the operating system or libraries do not always clean up everything perfectly so 16Gb can become 15.9Gb, and a request for all 16Gb would not succeed. Gradually, we are figuring out how to make sure the system leaves all 16Gb for us – so requiring still can seem like the way to go. That brings us to the second complication: memory oversubscription only happens at page allocation time, not memory allocation time. That can be a bit hard to wrap our heads around – but it ultimately means that “requiring” memory, and then running out of it, generally causes Linux to abort the program. What is the operating system to do when it runs out of memory? I expect interfaces for this will continue to evolve, but for now requiring MCDRAM will abort a program long after the allocation when the oversubscription actually happens. In contrast, preferring MCDRAM will silently switch to DDR when MCDRAM is exhausted.
autohbw
The autohbw library is an interposer library that redirects an application’s use of standard heap allocators (i.e., malloc(), calloc(), realloc(), posix_memalign(), and free()) to utilize MCDRAM. The decision of where to allocate is done purely based on size for each allocation within our application. The following example shows how to run an application such that allocations, ranging from 50K to 1M in size, will try to allocate from MCDRAM.

It is that easy, and it is that limited in abilities. This is often a better solution that numactl because it can be steered clear of small allocations and extraordinarily large allocations. Like numactl, autohbw does not require code changes to our application.
Autohbw is open source, so if you have clever ideas for doing more with it – by all means, have fun.
Being fully prescriptive: Memkind, hbw_malloc, FASTMEM
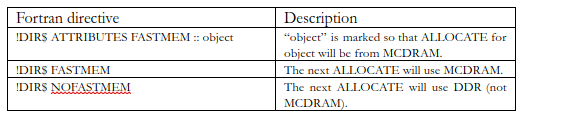
Full control comes to C/C++ by allocation routines specifically for MCDRAM memory, and it comes to FORTRAN by directives to modify ALLOCATE().
C programmers, courtesy of the memkind open source project, have MCDRAM versions of the standard heap allocation routines via the functions hbw_malloc(), hbw_calloc(), hbw_realloc(), hbw_free(), hbw_posix_memalign(), and hbw_posix_memalign_psize(). Each of these functions mimic the behavior of the standard routines (with the same names minus the “hbw_” prefix).
The hbw routines are specifically for high-bandwidth memory; the memkind APIs are a more generic interface that can support additional memory types in the future, as well as explicit DDR allocations. The advantage of the hbw routines is that they minimize the code changes needed – just add a prefix of “hbw_” for popular heap allocation library calls (i.e., malloc(), calloc(), realloc(), posix_memalign(), and free()). The advantage of the memkind interfaces is that they are more flexible for additional memory types. Ultimately, I think using hbw routines is the way to go unless you have a very specific need today to do otherwise.
The default policy is for these routines to “prefer” MCDRAM and not require it. It is possible to set a different policy using hbw_set_policy(HBW_POLICY_BIND). That can be done once in an application before any allocations are done. Attempts to set policy more than once will fail.
For C++ programmers, the memkind library comes with some excellent examples, one of which shows how to override new to create types that allocate into MCDRAM. Look in the examples directory for memkind_allocated_example.cpp and memkind_allocated_example.hpp.
For FORTRAN programmers, allocations are done using ALLOCATE(). Directives are used in Fortran to affect the behavior of ALLOCATE() in order to use “FASTMEM” (MCDRAM). There are also more advanced controls to set policies (preferred allocation vs. required allocation).
MCDRAM is direct mapped
It is worth noting that when used as a cache, MCDRAM acts as a direct mapped cache. This can be important to know when squeezing out ultimate performance. The decision to be direct mapped allowed higher performance and more capacity because of the available technology and simplicity of design possible for a direct mapped cache. While it would have been nice to have some associativity, it would have come with a cost to performance and capacity that reduced performance of applications. When travelling through multiple arrays simultaneously there is the possibility of additional conflict misses, due to the ‘direct mapping’ nature of the cache, which can be avoided by moving around alignments of data. That’s not my favorite optimization game to play, but it is effective when needed.
Summary
MCDRAM adds 16Gb of high bandwidth memory inside the Intel Xeon Phi processor (Knights Landing) package, which can flexibly be used as 8Gb memory + 8Gb cache, 12Gb memory + 4Gb cache, or 16Gb memory only.
When used as memory, there are a couple different ways to automatically shift allocations to the MCDRAM without changing an application. Of course, there are options to modify an application to directly allocate data into the MCDRAM memory as well. This is my second article about Intel Xeon Phi processors: the first was “Intel Xeon Phi processor Programming in a Nutshell” discussing how to think of the Intel Xeon Phi processor often referred to as Knights Landing. My next two articles will look at Cluster Modes and then vectorization with AVX-512.
 All Figures are adopted from the book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition, used with permission per lotsofcores.com.
All Figures are adopted from the book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition, used with permission per lotsofcores.com.

