
The Intel Omni-Path Architecture is the next-generation fabric for high-performance computing architectures. In this Sponsored Post, we will explore what makes a great HPC fabric and the workings behind IntelOmni-Path Architecture. Additional articles will cover HPC application needs, the platform makeup, and its impact in the Top500.
 What makes a great HPC fabric? Focusing on improving and enhancing application performance with fast throughput and low latency. To do this well means dealing with the details in fabric architecture. Intel OPA’s designers focused on the nuances of intelligent data movement—reducing latency, while ensuring packet and fabric integrity and scalability at speed. A key innovative approach is in Intel OPA’s link layer.
What makes a great HPC fabric? Focusing on improving and enhancing application performance with fast throughput and low latency. To do this well means dealing with the details in fabric architecture. Intel OPA’s designers focused on the nuances of intelligent data movement—reducing latency, while ensuring packet and fabric integrity and scalability at speed. A key innovative approach is in Intel OPA’s link layer.
Link Layer 1.5—An Innovative Approach
Enhancing the familiar seven-layer OSI networking model, where layer one is the physical wire and layer two is the data link encoding, Intel OPA’s unique approach essentially enhances transport control and efficiency with Link Layer 1.5. This layer allows Intel OPA to break up variably sized data streams into smaller fixed-sized flow control digits (called flits), which are packaged into fixed-sized Link Transfer Packets (LTPs). The maximum MTU is 10 kB instead of the traditional 4kB chunks, allowing for much larger transmissions when needed. This approach enables several key benefits.
Intel OPA’s designers focused on the nuances of intelligent data movement—reducing latency, while ensuring packet and fabric integrity and scalability at speed.
Low and deterministic latency—Mixed traffic on a network can behave like confused seas with the occasional rogue wave, as senders try to accommodate both large and low-priority flows (e.g. storage) with small and high-priority messages (e.g. MPI). Intel OPA’s Traffic Flow Optimization (TFO) delivers low, consistent, and deterministic latency for mixed traffic of various sizes by preempting transmissions at the smaller flit interval to inject a higher-priority message, if necessary. TFO removes any penalty for longer MTU sizes. The result is TFO turns those swells in traditional fabrics into small wavelets, while delivering consistent, deterministic, and dramatically reduced latency for high-priority traffic as shown in the figure.[1]
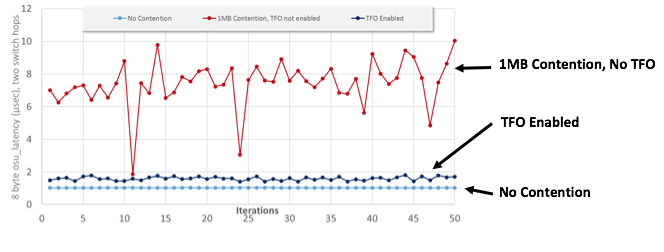
Penalty-free packet integrity—Two aspects of packet integrity slow down transmissions—error correction and end-to-end retries. Intel OPA’s Packet Integrity Protection (PIP) addresses both of these.
- Instead of using latency-inducing Forward Error Correction (FEC), PIP uses a CRC appended to the LTP to maintain high packet integrity with a zero-latency penalty for error detection. PIP is done in the switch hardware at each hop as the packet is decoded for the next send, so it does not add link overhead; error detection can happen at the 100 Gbps link rate.
- Instead of waiting for an error to propagate to an endpoint and the resulting acknowledgement of an end-to-end transmission or a server timeout, the Intel OPA sender implicitly assumes the sent message is correct unless told otherwise by the receiver. Resends are only necessary when the CRC is incorrect. End-to-end retries are expected to occur only once in 62,000 years for a 27,648-node cluster. This compares to retries every 2.7 hours when FEC is disabled and typical InfiniBand clusters have FEC disabled by default. FEC must be enabled to get equivalent protection.
Dynamic Lane Scaling—You don’t shut down the freeway for a fender bender. If one of Intel OPA’s four 25 Gbps lanes ever does fail, the entire fabric is not sacrificed with only a single lane being restored. Dynamic Lane Scaling in Intel OPA automatically reroutes traffic across the remaining three lanes to keep feeding the applications—without the need to reset the entire link.
Multi-modal Data Acceleration
For Intel OPA, application performance is what matters—how it can move data with the lowest latency and fastest speed. So, Intel OPA intelligently selects the best method of data transport available to it—setting up an RDMA channel using the host adapter or using the fast and efficient resources of the Intel Xeon processor to transfer data. The objective for Intel OPA is to benefit the application without delaying the flow.
Making Supercomputing More Valuable
Supercomputers are expensive, which is why if the performance improvements alone don’t get your attention, the price/performance of Intel Omni-Path Architecture will. Eliminating hardware and increasing capacity in switches drive down cost and improve efficiency. Intel OPA is already being tightly integrated with Intel processors, eliminating the need for discrete host fabric adapters. 48-port switches allow for the creation of a more efficient, tightly coupled cluster, while eliminating extra hardware to build the fabric. And, thinking of the app, fewer switches allows more budget for more compute nodes to enhance system performance, or even application software licenses. Intel OPA is a performance and price-performance winner.
App Performance Matters
It’s worth repeating: application performance is the only thing that’s important in HPC. From LAMMPS and ELMER/Ice to GADGET and beyond, Intel OPA will deliver up to nine percent higher performance, according to estimates.[2] And, with enhancements to code, like using Performance Scaled Messaging (PSM) and Intel MPI libraries, performance can improve considerably.
[clickToTweet tweet=”It’s worth repeating: application performance is the only thing that’s important in HPC. ” quote=”It’s worth repeating: application performance is the only thing that’s important in HPC. “]
Intel OPA is a complete fabric—host interface, switches, and software—optimized for HPC message passing, reduced latency, and uniform scalability to create complete, intelligent solutions for a full range of applications. In addition, compatibility and support for RDMA and OpenFabrics Software means no code porting is required to get the benefits of Intel OPA
What makes up the Intel OPA fabric? We’ll take a look at the entire solution next.
Find out more by reading the white paper or visiting www.intel.com/omnipath.
[1] Tests performed on Intel® Xeon® Processor E5-2697Av4 dual-socket servers with 2133 MHz DDR4 RAM per node. OSU OMB 4.1.1 osu_latency and osu_bibw with 1 MPI rank per node for each test. osu_bibw and osu_latency tests repeated in an indefinite loop and 50 iterations are sampled. Each host in osu_latency and osu_bibw test are connected to separate edge switch. The two edge switches are connected with 1 inter-switch link (ISL), so all traffic traverses the ISL. Open MPI 1.10.0 as packaged in IFS 10.0.0.0.697. Intel Corporation Device 24f0 – Series 100 HFI ASIC (B0 silicon). OPA Switch: Series 100 Edge Switch – 48 port (B0 silicon). For osu_latency, a virtual fabric (VF) enabled in opafm.xml with 30% bandwidth allocation and <PreemptRank>127</PreemptRank>. For osu_bibw, another VF is used with 50% bandwidth allocation and <PreemptRank>1</PreemptRank>. QOS=1 enabled for both VF. SmallPacket, LargePacket, and PreemptLimit set to 256,4096,and 4096, respectively.
[2] http://www.intel.com/content/www/us/en/high-performance-computing-fabrics/omni-path-architecture-application-performance-mpi.html

