This is the second post in a five-part series exploring the potential of unified deep learning with CPU, GPU and FGPA technologies. This post explores the possibilities and functions of deep learning software.

Download the full report.
Deep Learning Software
Machine learning applications are typically built using a collection of tools. Deep learning software frameworks are sets of software libraries that implement the common training and inference operations. Examples of these include Caffe/Caffe-2 (Facebook), TensorFlow (Google), Torch, PyTorch, and MxNet (used by Amazon). All of these are available as open source software. Such frameworks are supported across both GPUs and FPGAs, and can effectively hide most heterogeneity from application developers as well as enable portability across different systems.
DNN training is very computationally intensive and typically makes use of common floating-point computation functions such as Basic Linear Algebra Subprograms (BLAS), GEMV and GEMM routines, Conv2D operations, batch normalization, SGD, SVD, element wise matrix operations, and non-linear functions such as Softmax and ReLU. Availability of these building blocks along with an efficient data transfer mechanism between GPU and CPU is essential for the efficient implementation of these algorithms. Training is typically done on a combination of GPUs and CPUs using single-precision floatingpoint arithmetic (fp32), though the trend is to move towards half-precision (fp16) floating-point arithmetic. Recently, frameworks like MxNet allow scalable parallelization of training tasks using multiple CPUs and GPUs.
DNN training is very computationally intensive and typically makes use of common floating-point computation functions.
Middleware libraries provide operations to the frameworks that are tuned to specific hardware for maximum performance. MIOpen from AMD support the Radeon Instinct line of AMD GPUs. cuDNN from NVIDIA supports similar functions on NVIDIA GPUs. BLAS, FFT, and Random Number Generator (RNG) are a set of standard math library routines. NVIDIA Collective Communications Library (NCCL) implements multi-GPU and multi-node collective communication primitives.
AMD has recently announced the ROCm platform for GPUs. The ROCm platform includes system runtime functions and drivers, compilers, and porting software for CUDA programs to AMD’s Radeon line of GPUs. ROCm supports the common ML frameworks such as Caffe/Caffe-2, TensorFlow, Torch, and MxNet to provide a “full-stack” solution. ROCm is also compliant with the Heterogeneous Systems Architecture (HSA) open standard, and scales to multi-GPU configurations.
The complete machine learning software stack, featuring AMD’s ROCm and MIopen, is shown below.
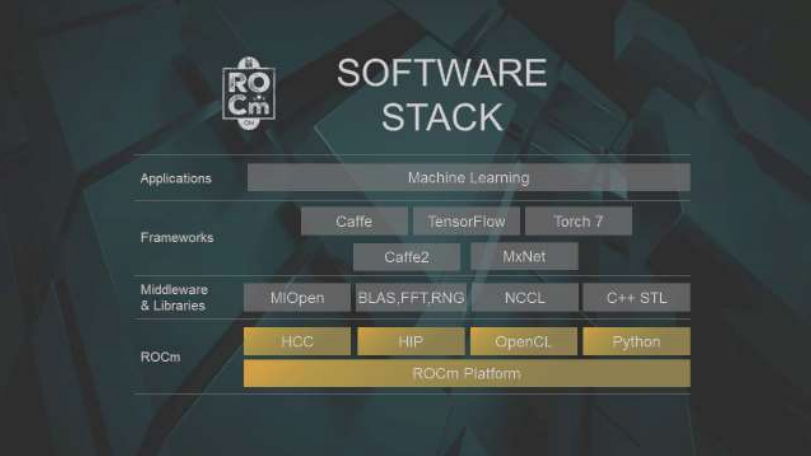
ROCm Software Stack including MIOpen and common MI frameworks.
Inference implementation on FPGAs typically uses fused mode of operations, where most of the network is implemented using large and flexible on-chip memory and flexible arithmetic capabilities which are unique to Xilinx FPGA. Xilinx and its partners have implemented optimized overlay engines for implementing CNN and RNN engines. xfDNN from Xilinx provides a software middleware which runtime, compiler, and a quantizer to map and run DNN models trained on GPUs and CPUs onto optimized overlay engines for CNN and RNN processing. Xilinx also provides Reconfigurable Acceleration Stack, which consists of the pre-built hardware platform on FPGA, a runtime and design tools to enable development of a broad set of customized deep learning solutions.
A long-term vision for application developers is a full and seamless programing environment that works across CPUs, GPUs, and FPGAs. This could initially focus on support for a common language and runtime, such as OpenCL, and later be extended to additional languages. The language support could hide any internal differences in compilers and runtimes between the CPU, GPU, and FPGA implementations.
Moreover, this seamless programming environment will facilitate the full end-to-end optimization of resource allocation to take maximum advantage of the collection of available compute and memory capability of the system.
Over the next few weeks, this series will also cover the following topics:
- The Machine Learning Potential of Combining Technologies
- The Ins and Outs of DNN Implementation and Optimization
- Computational Approaches – CPU, GPU, and FPGA
- Unified Deep Learning Configurations and Emerging Applications
You can download the full report here, courtesy of AMD and Xilinx, “Unified Deep Learning with CPU, GPU and FPGA technology.”

