Sponsored Post
![]()
To satisfy the increasing demand for a unified platform for big data analytics and deep learning, Intel recently released BigDL. It’s an open source, distributed, deep learning framework for Apache Spark*.
The BigDL library sits on top of Spark. It allows easy scale-out computing so that users can develop deep learning applications as standard Spark programs that run directly on top of existing Spark or Hadoop* clusters:
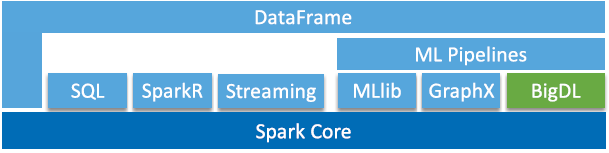 BigDL provides complete support for numeric computing and high-level neural networks, so users can load pre-trained Caffe* or Torch models into their Spark deep learning applications.
BigDL provides complete support for numeric computing and high-level neural networks, so users can load pre-trained Caffe* or Torch models into their Spark deep learning applications.
To achieve the highest performance, BigDL employs the Intel® Math Kernel Library (Intel MKL) and multithreading with each Spark task. It is orders of magnitude faster than out-of-the-box open source Caffe, Torch, or TensorFlow* on a single-node Intel® Xeon® processor and can attain performance levels comparable with mainstream GPUs.
By leveraging Apache Spark and an optimized implementation of synchronous SGD and all-reduce communication, BigDL can efficiently scale out to perform data analytics at truly big-data scale.
Building BigDL on top of Spark makes it easy to distribute model training, which is the most computationally intensive part of deep learning. Instead of requiring the developer to explicitly distribute the computation in their application, BigDL spreads the work across the Spark cluster automatically.
BigDL supports Hadoop and Spark as unified data analytics platforms that provide data storage, data processing and mining, feature engineering, classical machine learning, and deep learning capabilities. This makes deep learning more accessible to big data users and data scientists.
Open source Intel BigDL provides the following abstractions and APIs:
|
Name |
Descriptions |
|
Tensor |
Multidimensional array of numeric types (e.g., Int, Float, Double) |
|
Module |
Individual layers of the neural network (e.g., ReLU, Linear, SpatialConvolution, Sequential) |
|
Criterion |
Given input and target, computing gradient per given loss function |
|
Sample |
A record consisting of feature and label, each of which is a tensor |
|
DataSet |
Training, validation, and test data; one may use Transformer to perform series of data transformations (w/ -> operators) on DataSet |
|
Engine |
Runtime environment for the training (e.g., node#, core#, spark versus local, multithreading) |
|
Optimizer |
Stochastic optimizations for local or distributed training (using various OptimMethod such as SGD, AdaGrad) |
Table 1. BigDL abstractions and APIs
A BigDL program can run either as a local Scala/Java* program or as a Spark program. Python* support will be available shortly.
The high performance and scalability of BigDL makes Hadoop/Spark into a unified platform for data storage, data processing and mining, feature engineering, traditional machine learning, and deep learning workloads, resulting in better economy of scale, higher resource utilization, ease of use/development, and better TCO.

