
“Over two decades, Intel continued its efforts to refine libraries optimized to coax the greatest performance from Intel® processors. In this video, Noah Clemons, staff technical consulting engineer at Intel talks about the latest specialized libraries and their contributions for highly-optimized applications.”
Deep Learning Open Source Framework Optimized on Apache Spark*
July 9, 2018 by
Intel recently released BigDL. It’s an open source, highly optimized, distributed, deep learning framework for Apache Spark*. It makes Hadoop/Spark into a unified platform for data storage, data processing and mining, feature engineering, traditional machine learning, and deep learning workloads, resulting in better economy of scale, higher resource utilization, ease of use/development, and better TCO.
Intel MKL Speeds Up Automated Driving Workloads on the Intel Xeon Processor
March 8, 2018 by
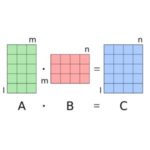
The automated driving developer community typically uses Eigen*, a C++ math library, for the matrix operations required by the Extended Kalman Filter algorithm. EKF usually involves many small matrices. However most HPC library routines for matrix operations are optimized for large matrices. “Intel MKL provides highly-tuned xGEMM function for matrix-matrix multiplication, with special paths for small matrices. Eigen can take advantage of Intel MKL through use of a compiler flag. A significant speedup results when using Eigen and Intel MKL and compiling the automated driving apps with the latest Intel C++ compiler.”
Intel MKL Compact Matrix Functions Attain Significant Speedups
February 22, 2018 by
The latest version of Intel® Math Kernel Library (MKL) offers vectorized compact functions for general and specialized matrix computations of this type. These functions rely on true SIMD (single instruction, multiple data) matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats.
Intel MKL Speeds Up Small Matrix-Matrix Multiplication for Automatic Driving
January 25, 2018 by
Certain applications, such as automated driving, require low latency small matrix-matrix multiplication in real time. They use specialized libraries that can be customized for small matrix operations. Recompiling and linking those libraries with the highly optimized DGEMM routine in the Intel® Math Kernel Library 2018 can give speedups many times over native libraries.
Speeding Up Big Data Analysis With Intel MKL and Intel DAAL
July 27, 2017 by

“New algorithms that can query massive amounts of data an draw conclusions have been developed, but these algorithms need to be optimized on the underlying hardware. This is where the expertise of vendors who develop the hardware can add tremendous value. Optimizing the underlying libraries that can execute with a high degree of parallelism will definitely lead to improved performance for the software and productivity gains for the organization.”
Performance Gains Using Libraries
June 29, 2017 by
In many cases, applications that perform various simulations use some of the same math functions that many other applications use. Rather than each developer recoding the same math functions over and over, libraries, developed by experts can significantly speed up execution of the overall application. Since there can be many optimizations that experts who understand many of the nuances of the hardware would understand, it is important that developers be familiar with various libraries that are made available for HPC types of applications.
Deep Learning Frameworks Get a Performance Benefit from Intel MKL Matrix-Matrix Multiplication
June 22, 2017 by

Intel® Math Kernel Library 2017 (Intel® MKL 2017) includes new GEMM kernels that are optimized for various skewed matrix sizes. The new kernels take advantage of Intel® Advanced Vector Extensions 512 (Intel® AVX-512) and achieves high GEMM performance on multicore and many-core Intel® architectures, particularly for situations arising from deep neural networks..
Intel Processors for Machine Learning
May 4, 2017 by

Machine Learning is a hot topic for many industries and is showing tremendous promise to change how we use systems. From design and manufacturing to searching for cures for diseases, machine learning can be a great disrupter, when implemented to take advantage of the latest processors.
Intel MKL and Intel TBB Working Together for Performance
March 23, 2017 by
When used in a TBB environment, Intel has demonstrated a many-fold performance improvement over the same parallelized code using Intel MKL in an OpenMP environment. Intel TBB-enabled Intel MKL is ideal when there is heavy threading in the Intel TBB application. Intel TBB-enabled Intel MKL shows solid performance improvements through better interoperability with other parts of the workload.

