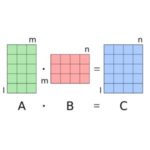
Certain applications, such as automated driving, require low latency small matrix-matrix multiplication in real time. They use specialized libraries that can be customized for small matrix operations. Recompiling and linking those libraries with the highly optimized DGEMM routine in the Intel® Math Kernel Library 2018 can give speedups many times over native libraries.
Concurrent Kernel Offloading
June 12, 2015 by

“The combination of using a host cpu such as an Intel Xeon combined with a dedicated coprocessor such as the Intel Xeon Phi coprocessor has been shown in many cases to improve the performance of an application by significant amounts. When the datasets are large enough, it makes sense to offload as much of the workload as possible. But is this the case when the potential offload data sets are not as large?”
