Sponsored Post
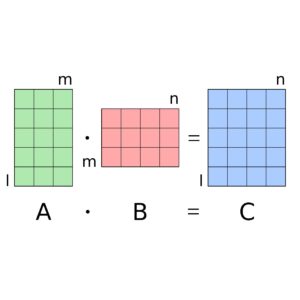
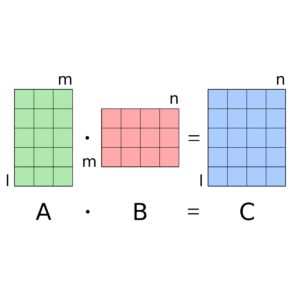 Nearly all big science, machine learning, neural network, and machine vision applications employ algorithms that involve large matrix-matrix multiplication. But multiplying large matrices pushes the number of floating point operations and the amount of data motion to rapidly become unmanageable And because this type of computation is so common, the biggest performance challenge for many years has been optimizing matrix-matrix multiplication for such really large matrices,.
Nearly all big science, machine learning, neural network, and machine vision applications employ algorithms that involve large matrix-matrix multiplication. But multiplying large matrices pushes the number of floating point operations and the amount of data motion to rapidly become unmanageable And because this type of computation is so common, the biggest performance challenge for many years has been optimizing matrix-matrix multiplication for such really large matrices,.
But a number of applications involve repeated multiplication of many small matrices, which presents its own unique optimization issues.
One such application area is automated driving, where the constant high speed stream of perception data, direction prediction, and vehicle control must be done in real time with a very tight latency allowance that must be met nearly 100 percent of the time.
The size of the matrices involved in these calculations tend to be small, on the order of 2×2 to 4×4, or where i+m+n is less than 20. So from the start, using math libraries optimized for large matrices would be the wrong approach.
In the particular case of automated driving, most applications use specialized libraries that can be customized for small matrix operations. And in most cases, these libraries ultimately call an optimized version of the Basic Linear Algebra Subroutine (BLAS) library DGEMM (Double-precision GEneral Matrix Multiplication).
Developers have found that by recompiling and linking those libraries with the highly optimized DGEMM routine in the Intel® Math Kernel Library 2018 (Intel MKL 2018) can give speedups many times over native libraries.
[clickToTweet tweet=”Automated driving applications benefit from Intel MKL without needing any modification of the code.” quote=”Automated driving applications benefit from the latest Intel MKL GEMM without any modification.”]
Intel MKL 2018 provides highly optimized, threaded, and vectorized math functions that maximize performance on Intel processor architectures. It is compatible across many different compilers, languages, operating systems, linking, and threading models. In particular, the Intel MKL DGEMM function for matrix-matrix multiplication is highly tuned for small matrices. To eliminate overhead, Intel MKL provides a compiler flag to guarantee that the fastest code path is used at runtime.
Intel MKL primitives take advantage of Intel Advanced Vector Extensions 512 (Intel AVX-512) and the capabilities of the latest generations of the Intel Xeon PhiTM processors. GEMM chooses the code path at runtime based on characteristics of the matrices and the underlying processor’s capabilities. As a result, applications that rely on GEMM will automatically benefit from these optimizations without needing any modification of the code merely be relinking with Intel MKL.
Intel MKL 2018, part of Intel Parallel Studio XE 2018, includes all the standard BLAS, PBLAS, LAPACK, ScaLAPACK, along with specialized Deep Neural Network functions (DNN), optimized for the latest Intel® architectures.
Download the free Intel® Math Kernel Library now or Intel® Parallel Studio XE.

