One of the big surprises of the past few years has been the spectacular rise in the use of Python* in high-performance computing applications. With the latest releases of Intel® Distribution for Python, included in Intel® Parallel Studio XE 2019, the numerical and scientific computing capabilities of high-performance Python now extends to machine learning and data analytics.
Python Can Do It
April 9, 2018 by
“Python remains a single threaded environment with the global interpreter lock as the main bottleneck. Threads must wait for other threads to complete before starting to do their assigned work. The result of this model is that production code is produced that is too slow to be useful for large simulations.”
Outliers – Why So Important for Data Analytics?
February 1, 2018 by
Data analytics deals with making observations with various data sets, and trying to make sense of the data. When dealing with very large data sets, automated tools must be used to find patterns and relationships. One of the most important tasks from large data sets is to find an outlier, which is defined as a sample or event that is very inconsistent with the rest of the data set.
Speeding Up Big Data Analysis With Intel MKL and Intel DAAL
July 27, 2017 by

“New algorithms that can query massive amounts of data an draw conclusions have been developed, but these algorithms need to be optimized on the underlying hardware. This is where the expertise of vendors who develop the hardware can add tremendous value. Optimizing the underlying libraries that can execute with a high degree of parallelism will definitely lead to improved performance for the software and productivity gains for the organization.”
Go with Intel® Data Analytics Acceleration Library and Go*
July 20, 2017 by
Use of the Go* programming language and it’s developer community has grown significantly since it’s official launch by Google in 2009. Like many popular programming languages (C and Java come to mind), Go started as an experiment to design a new programming language that would fix some of the common problems of other languages and yet stay true to the basic tenets of modern programming: be scalable, productive, readable, enable robust development environments, and support networking and multiprocessing.
Performance Gains Using Libraries
June 29, 2017 by
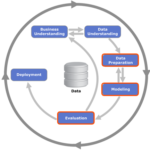
In many cases, applications that perform various simulations use some of the same math functions that many other applications use. Rather than each developer recoding the same math functions over and over, libraries, developed by experts can significantly speed up execution of the overall application. Since there can be many optimizations that experts who understand many of the nuances of the hardware would understand, it is important that developers be familiar with various libraries that are made available for HPC types of applications.
Intel DAAL Accelerates Data Analytics and Machine Learning
February 23, 2017 by

Intel DAAL is a high-performance library specifically optimized for big data analysis on the latest Intel platforms, including Intel Xeon®, and Intel Xeon Phi™. It provides the algorithmic building blocks for all stages in data analysis in offline, batch, streaming, and distributed processing environments. It was designed for efficient use over all the popular data platforms and APIs in use today, including MPI, Hadoop, Spark, R, MATLAB, Python, C++, and Java.
A Decade of Multicore Parallelism with Intel TBB
January 12, 2017 by

While HPC developers worry about squeezing out the ultimate performance while running an application on dedicated cores, Intel TBB tackles a problem that HPC users never worry about: How can you make parallelism work well when you share the cores that you run upon?” This is more of a concern if you’re running that application on a many-core laptop or workstation than a dedicated supercomputer because who knows what will also be running on those shared cores. Intel Threaded Building Blocks reduce the delays from other applications by utilizing a revolutionary task-stealing scheduler. This is the real magic of TBB.
Optimizing Your Code for Big Data
December 8, 2016 by

Libraries that are tuned to the underlying hardware architecture can increase performance tremendously. Higher level libraries such at the Intel Data Analytics Acceleration Library (Intel DAAL) can assist the developer with highly tuned algorithms for data analysis as well as machine learning. Intel DAAL functions can be called within other, more comprehensive frameworks that deal with the various types of data and storage, increasing the performance and lowering the development time of a wide range of applications.
Better Software For HPC through Code Modernization
September 15, 2016 by
Vectorization and threading are critical to using such innovative hardware product such as the Intel Xeon Phi processor. Using tools early in the design and development processor that identify where vectorization can be used or improved will lead to increased performance of the overall application. Modern tools can be used to determine what might be blocking compiler vectorization and the potential gain from the work involved.
