TIGER supercomputer at Princeton’s 47,000-square-foot data center. Photo by Florevel Fusin-Wischusen, Princeton Institute for Computational Science and Engineering.
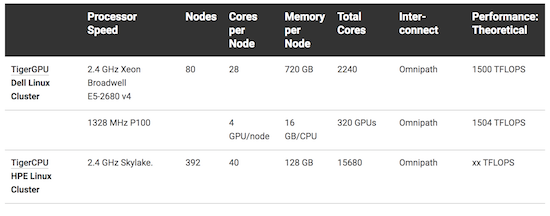
Princeton’s new flagship TIGER supercomputer is now up and running at their High-Performance Computing Research Center (HPCRC). As a hybrid system, TIGER is built from a combination of Intel Skylake chips and NVIDIA Pascal P100 GPUs, adding up to a peak performance of 2.67 Petaflops peak performance.
Computation has become an indispensable tool in accomplishing that mission,” Dominick said. “With the newest addition to our High-Performance Computing suite, Princeton continues to equip its faculty with the most advanced computational tools available. The TIGER cluster, and the remarkable staff that support it, are symbolic of the University’s commitment to sustained excellence.”
TIGER has a total of 15,680 processors available, with 40 per node. Each node contains at least 192 GB of memory (4.8 GB per core). The nodes are assembled into 24 node chassis where each chassis has a 1:1 Omnipath connection. There are also 40 nodes with memory of 768 GB (19 GB per core). These larger memory nodes have SSD drives for faster I/O locally.
All TIGER nodes are connected through Intel Omni Path switches for MPI traffic, GPFS, and NFS I/O and over a Gigabit Ethernet for other communication.