By Timothy Prickett Morgan • Get more from this author
 GPU chipmaker Nvidia knows that it has to do more to grow its Tesla biz than slap some passive heat sinks on a fanless GPU card and talk up its CUDA parallel-programming tools. It has to keep delivering price/performance improvements, as well.
GPU chipmaker Nvidia knows that it has to do more to grow its Tesla biz than slap some passive heat sinks on a fanless GPU card and talk up its CUDA parallel-programming tools. It has to keep delivering price/performance improvements, as well.
And that’s exactly what it’s doing with the new Tesla M2090 GPU coprocessor.
Back when the “Fermi” GPU chips were previewed at the SC2009 supercomputing event a year and a half ago, Nvidia showed off a chip with 512 cores, plus L1 and L2 cache memories for those cores (this was new) and ECC memory scrubbing (also new). The design bundled up 16 sets of 32 cores each into a streaming multiprocessor with 64KB of L1 cache, and a higher level L2 cache weighing in at 768KB that the cores can share.
That Fermi chip sported GDDR5 memory controllers, and the cards using the Fermi chips (either as discrete graphics cards or GPU coprocessors for accelerating floating point calculations) could have 3GB or 6GB of main memory. The memory controllers on the Fermi GPUs can address up to 1TB of memory, in theory.
But in the chip racket, theory does not always happen on the first iteration of a product, and so it was with the Fermi GPUs.
When the Fermi chips started shipping in the Tesla line of GPU coprocessors in May 2010, the initial Teslas had only 448 cores activated. Nvidia never explained this, but most people surmised that this had to do with yield issues (gunk on some cores in the chip) and the chips generating too much heat at a particular clock speed.
With those 448 cores running at 1.15GHz and GDDR5 memory chips running at 1.56GHz, the Tesla M2050 GPU coprocessor was rated at the 515 gigaflops of double-precision and 1.03 teraflops single-precision when performing floating-point operations.
The Tesla M2050 is a single-wide PCI-Express 2.0 device that has 3GB of GDDR5 memory, while the M2070 is a two-slot device that packs 6GB of memory and has the same floppish performance.
Both are rated at a top-end 225 watts of peak power draw, but Nvidia says the actual heat thrown off by the device is often a lot less and depends on the workload. That is a little bit less than 238 watts that the Tesla C2050 and C2070 coprocessors, which have fans built into them and which are aimed at goosing the number-crunching power of workstations to create a “personal supercomputer” – although these devices, too, are rated at the same 515 gigaflops of double-precision and 1.03 teraflops single-precision.
Sumit Gupta, senior product manager of the Tesla line at Nvidia, says that the Fermi GPUs used in the new M2090 coprocessors are not just a bin sort, looking for Fermis with more working cores or clocks that can run faster reliably. Nvidia has actually done a new tape-out of the Fermi design using Taiwan Semiconductor Manufacturing Corp’s 40-nanometer processes, which Gupta says have some improvements that make chips run better.
When you add up some nips and tucks here and there on the Fermi chip plus the process improvements from TSMC, Nvidia can crank up the Fermi core clock speed by 13 per cent to 1.3GHz, and the GDDR5 memory speed by 18.6 per cent, to 1.85GHz, on the Tesla M2090.
 Nvidia’s Tesla M2090 server GPU coprocessor
Nvidia’s Tesla M2090 server GPU coprocessor
Those increases help performance considerably. And so does the fact that with the TSMC process improvement, Nvidia can now have all 512 cores in the Fermi design activated, which yields a theoretical 14.3 per percent improvement over those initial Fermi chips with only 448 active cores.
Do the math
When you add it up, the faster clocks and memory and the higher core count add up to somewhere between a 20 and 30 per cent improvement in performance, thus:
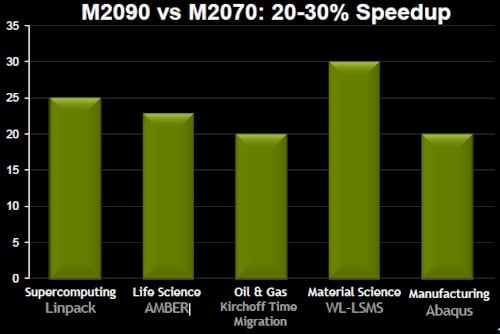 Tesla M2090: Your performance improvement may vary
Tesla M2090: Your performance improvement may vary
By the raw numbers, the M2090 is rated at 665 gigaflops at double-precision and 1.33 teraflops at single-precision, or 29.1 per cent more than the M2070 it replaces. The M2090 delivers 178GB/sec of memory bandwidth, up from 148GB/sec with the M2070.
And here’s the kicker: the M2090s go faster but are still within the same 225 watt peak power draw of the earlier and slower M2050 and M2070 devices. Of course, your actual power draw will depend on the workload and how it stresses the GPU coprocessor.
But its not just speed and power requirements that are pushing the coprocessor envelope: the big innovation that is helping with the adoption of GPU accelerators for supercomputing and other analytics jobs is not the GPU, but the server that wraps around them.
“We’re beginning to see server makers respond to what customers want,” Gupta tells El Reg. “Once customers start using GPUs, they want more GPUs in a box and fewer CPUs.”
Gupta calls out HP’s new ProLiant SL390s G7, which can cram eight GPUs into a two-socket tray server in a half-width 4U tray, which was soft-launched back in April. The Tesla M2050 and M2070 GPU coprocessors were already certified in this machine, as is the new M2090. That full configuration gives customers a ratio of four GPUs per socket – but, oddly enough, this is not actually good enough. For most HPC applications, one GPU per CPU core is what the applications really need, says Gupta.
On a two-socket server, if you backstep from a six-core Xeon 5600 to a four-core model (such as the Xeon X5667 launched in February), you can get things into balance. At least until there is an eight-core Xeon chip.
Perhaps the better answer, you’re thinking, might be to do what Nvidia has already done for workstation graphics back at the end of March, and double-up the GPUs on a double-wide card.
The GTX 590 graphics card has two 512-core Fermi chips running at 1.22GHz with 1.5GB of GDDR5 memory per chip running at 1.77GHz. Nvidia does not provide floating-point performance ratings on the GTX 590, but it should be somewhere around 1.24 teraflops double-precision. With six of these GTX 590 cards in a 3U chassis, an HP ProLiant SL390s would be able to use six-core Xeon 5600 chips and have one GPU per CPU core.
The only trouble is, however, that the GTX 590s are aimed at workstations, not servers, and have fans on them that might mess up the airflow in the server chassis. Moreover, the GTX 590 cards pull down 365 watts of power, and are therefore a bit more power dense than the M2090, which has half as many GPUs but four times as much GDDR5 memory per Fermi chip. If your HPC app needs more GPU and less GPU memory, this is worth thinking about, if your server can handle the cooling job on multiple GTX 590s – and you can actually get your hands on them.
The GTX 590 will win, hands down, on price, at $699. The M2090 is probably going to costsomewhere around $4,100 to $4,700, if it is priced like the M2070 it replaces. Nvidia does not provide official pricing on the fanless M20 series of GPU coprocessors, which is silly.
Last week, Nvidia CEO Jen-Hsun Huang lamented that the Professional Solutions business, where workstation graphics and Tesla co-processors live inside Nvidia, was not doing as well as expected, and part of the problem would seem to be that Nvidia is trying to charge too much money for the fanless GPUs. The price disparity between the GTX 590 and the M2090 is too large, plain and simple. ®
This article originally appeared in The Register.


“Nvidia does not provide floating-point performance ratings on the GTX 590, but it should be somewhere around 1.24 teraflops double-precision.”
Actually it is a dirty little secret that DP performance on GeForce cards is crippled (Wikipedia does have a line “For consumer products, double precision performance has been limited to a quarter of that of the “full” Fermi architecture.”). For DP that is half of FP you need to go to Quadro or Tesla hardware.
Nice article.
Although as ce107 says, you’re not going to be able to use desktop graphics cards like the GTX 590 as you are limited to 1/4 of the DP that you get in the server cards (this is an intentional and artificial change apparently).
This is really quite tragic. If we want to realize the dream of every researcher having access to a “super-computer”, it would be ideal to simply have a desktop computer packed with a pair of GTX 590s cranking out the calculations. I wonder how much of a market there for something inbetween the common gaming desktop and the HPC server? Could we convince nVidia to supply consumer cards with full DP unlocked?