
Sponsored Post
Through the microarchitecture improvements, increased core counts, and faster memory speeds of the new Intel® Xeon® processor E5-2600 v4 product family based on the “Broadwell” microarchitecture, you can increase your HPC application performance by up to 47%*. You will see significantly improved per-core performance with these just announced Intel® Xeon® processors that can then be multiplied by parallel programs that utilize the number of cores available inside these processors (e.g. up to 22 in the Intel® Xeon® processor E5-2600 v4 product family). Improvements to the memory and virtual memory capabilities – including the ability to utilize faster DDR4-2400 memory – means that these processors can speed all aspects of your application from IO DMA operations, to processing serial sections of code, as well as delivering increased performance on both task- and data-parallel applications.
“HPC has become a ubiquitous and fundamental tool for developing insight, whether it’s in traditional sciences, large enterprises, small and mid-size businesses, or for emerging usages” – Hugo Saleh, Director of Marketing, Intel High Performance Computing Platform Group
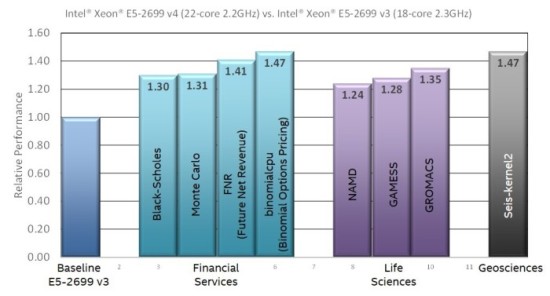
Figure 1: Performance on a variety of HPC applications*
Advances in the microarchitecture can significantly increase the per core vector performance of HPC applications including structural analysis and computational fluid dynamics (CFD) codes to name but two. This is important as even applications that cannot be recompiled as well as those that do not scale well or that have hit a scaling bottleneck will benefit from the microarchitecture improvements. For example, a vector floating-point multiply now only takes 3 clock cycles as opposed to the 5 clock cycles required by the previous generation microarchitecture. Hugo Saleh, Director of Marketing, Intel High Performance Computing Platform Group, notes, “For HPC that is going to be a pretty big improvement”. Similarly, the performance of radix-1024 and scalar divides have been improved plus the ADC (Add with carry), SBB (Subtract with Borrow), and PCLMULQDQ (Carry-Less Multiplication Quadword instructions now complete in one clock cycle**.
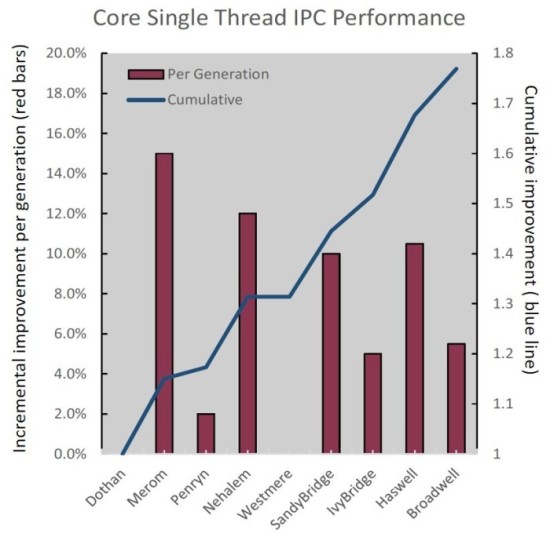
Figure 2: Single thread IPC performance*
Deep learning (both during the training and prediction phases) plus a vast array of linear and matrix-multiply based applications will particularly benefit from the FMA (Fused Multiply-Add) instruction introduced in the previous generation microarchitecture coupled with the improved vector multiply performance of the new Intel Xeon CPU microarchitecture.
Other Intel Xeon processor microarchitecture advances include memory improvements such as DDR4-2400 memory support, and improvements to the virtual memory translation lookaside buffer (TLB) that improve address prediction for branches and returns, reduce instruction latencies, provide a larger out-of-order scheduler, increase the size of the STLB (from 1k to 1.5k entries), plus more. These improvements help the memory subsystem keep pace with the improved processing capabilities of these next generation Intel® processors.
The per-core microarchitecture improvements can help make HPC applications run significantly faster – including those applications that cannot be recompiled and those that do not scale well to large numbers of cores!
HPC users will be thrilled that the hardware assist for vector gather results in approximately 60% fewer ops. In addition, the Intel® AVX instructions have been optimized so that a core running these instructions does not automatically decrease the max turbo frequency of other cores in the socket running non-AVX codes. This can translate to increased mixed workload performance.

Figure 3: Advantage of the Broadwell microarchitecture for mixed workloads**
The new ADCX/ADOX instructions supported by the new Intel Xeon processor microarchitecture increase the performance of public key cryptography (e.g., RSA) for secure data transport as well as large multi-precision integer arithmetic libraries. The microarchitecture also supports the RDSEED instruction, which generates 16-, 32- or 64-bit random numbers from a thermal noise entropy stream according to NIST SP 800-90B and 800-90. This instruction can provide a strong source to seed another pseudorandom number generator for security, Monte Carlo, and a wide variety of other applications.
It is well worth benchmarking the new Intel Xeon processor E5-2600 v4 product family to see the performance they can deliver on your applications. Even those customers running previous generation Intel Xeon processor E5-2600 v3 product family can potentially see a 47% performance increase*. Upgrades can be simple as these new processors are socket compatible with the Grantley platform. It’s an easy way to significantly bump the performance of your HPC computational nodes!
The new Intel Xeon processor E5-2600 v4 product family is Intel’s first processor within Intel® Scalable System Framework, a holistic approach that incorporates Intel’s existing and next-generation of compute, memory/storage, fabric, and software products, including Intel Xeon processors, Intel® Xeon Phi™ processors, Intel® Enterprise Edition for Lustre* software, and Intel® Omni-Path Architecture. When used in combination with the Intel Xeon processor E5-2600 v4 product family, Intel Omni-Path Fabric delivers up to 24% higher message rate***, delivering balanced HPC system performance.
Learn more about the new Intel® Xeon® processor E5 family.
* Binomial Options Pricing tests performed by Intel on Intel® Xeon® processor E5-2699 v4 (22-core 2.2GHz) dual-socket servers with 2400 MHz DDR4 memory (Intel® Turbo Boost Technology enabled and Intel® Hyper-Threading Technology enabled, Red Hat Enterprise Linux* server v6.4) and Intel® Xeon® processor E5-2699 v3 (18-core 2.3GHz) dual-socket servers with 2133MHz DDR memory (Intel® Turbo Boost Technology enabled and Intel® Hyper-Threading Technology enabled, Red Hat Enterprise Linux* server v6.4). Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance.
** Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmarkand MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.For more complete information visit http://www.intel.com/performance. Results shown are based on detailed models of the core created by Intel. The models simulations utilize over a thousand instruction sequences which are believed to approximate the expected behavior of a wide range of customer applications. They are estimates and for informational purposes only.
*** Tests performed by Intel on Intel® Xeon® processor E5-2699 v4 (22-core 2.2GHz) dual-socket servers with 2133 MHz DDR4 memory (Intel® Turbo Boost Technology enabled and Intel® Hyper-Threading Technology disabled, Red Hat Enterprise Linux* server v7.2, Intel® Fabric Suite 10.0.0.0.697, 44 cores per node) and Intel® Xeon® processor E5-2699 v3 (18-core 2.3GHz) dual-socket servers with 2133 MHz DDR4 memory (Intel® Turbo Boost Technology enabled and Intel® Hyper-Threading Technology enabled, Red Hat Enterprise Linux* server v7.1, Intel® Fabric Suite 10.0.0.0.697, 36 cores per node). 8 byte message rate with OSU OMB 4.4.1. osu_mbw_mr and modified for bi-directional measurement. Open MPI 1.10.0-hfi as packaged in Intel Fabric Suite 10.0.0.0.697. IOU Non-Posted Prefetch disabled in BIOS. snp_holdoff_cnt=9 in BIOS. Intel® OPA B0 HFI, 100 series, 1 Port PCIe x16. Intel® OPA 100 Series B0 Edge switch. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance.
