In this special guest feature, Rob Farber writes that a study done by Kyoto University Graduate School of Medicine shows that code modernization can help Intel Xeon processors outperform GPUs on machine learning code.

Rob Farber
The Kyoto University Graduate School of Medicine determined that a dual-socket Intel Xeon E5-2699v3 (Haswell architecture) system delivers better performance than an NVIDIA K40 GPU when training deep learning neural networks for computational drug discovery using the Theano framework. Theano is a Python library that lets researchers transparently run deep learning models on CPUs and GPUs. It does so by generating C++ code from the Python script for the destination architecture. The generated C++ code can also call optimized math libraries.
The Kyoto University team recognized that the performance of the open source Theano C++ multi-core code could be significantly improved. They worked with Intel to improve Theano multicore performance using a dual-socket Intel Xeon processor based system as the next generation Intel Xeon Phi processors were not available at that time. The optimized performance improvement turned out to be significant and demonstrated that a dual-socket Haswell processor chipset can outperform an NVIDIA K40 GPU on deep learning training tasks[1].
On the basis of the Intel Xeon processor benchmark results presented by Masatoshi Hamanaka (Research Fellow) at the 2015 Annual conference of the Japanese Society for Bioinformatics (JSBI 2015) and the consistency of the multi- and many-core runtime environment, GPUs were eliminated from consideration as they added needless cost, complexity, and memory limitations without delivering a deep learning performance benefit.
A summary slide from the presentation is shown below.

Figure 2: Speedup of optimized Theano relative to GPU plus impact of the larger Intel Xeon memory capacity. (Results courtesy Kyoto University)
The Kyoto deep learning cluster procurement will act as a bellwether as it is the first first prominent system to select many-core CPU over GPU technology. According to all expectations, the Theano software will run much faster on the next generation Intel Xeon Phi processors.
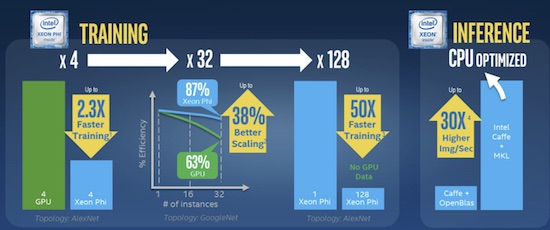
Figure 3: At ISC’16, Intel provided details on the superior performance of Intel Xeon Phi compared to GPUs for deep learning
Importance of the science
The Kyoto University Graduate School of Medicine is applying various machine learning and deep learning algorithms to problems in life sciences including drug discovery, medicine, and health care. As with other fields, the Kyoto researchers are faced with vast amounts of data. For example, the Kyoto team wishes to apply machine learning to data produced by experimental technologies such as high-throughput screening (HTS) and next-generation sequencing (NGS). In addition, electronic health records (EHR) from daily clinical practice can be analyzed. The Kyoto team believes they can perform a more thorough analysis than other efforts through their use of big-data machine-learning technology compared to previous approaches.
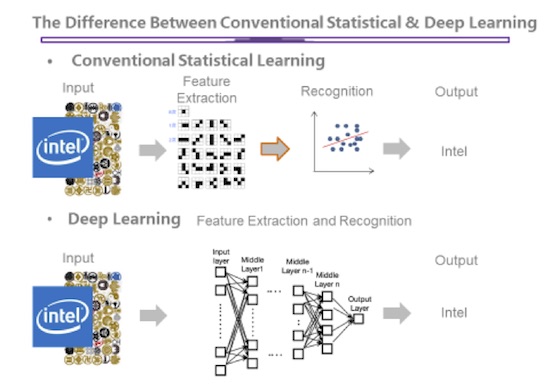
Figure 4: Illustration showing how deep learning differs from conventional approaches. (Image courtesy Kyoto University)
Kyoto has two goals for their machine learning and deep-learning study: (1) Make knowledge discoveries from the rapidly increasing data generated by the experiments and electronic data that is now being collected at the patient’s bedside, and (2) improve drug discovery and patient health care by returning relevant information from their knowledge discoveries to both experimentalists and physicians.
“Many clinical applications during the next decade will adopt machine learning technology,” said Professor Yasushi Okuno. “Our application of machine learning and deep-learning will become increasingly important over the next ten years.”
The Kyoto drug discovery workload
Part of the Kyoto workload will apply computational virtual screening to the field of drug discovery. Virtual screening is used in early stage of drug discovery process, a process which usually take ten years or more. The purpose of virtual screening is to computationally screen huge numbers of chemical compounds to find new drug candidates.
“Currently, this early stage of drug discovery takes several years and a few hundred million dollars,” explained Professor Okuno. “But we believe our study will significantly decrease both time and cost.”
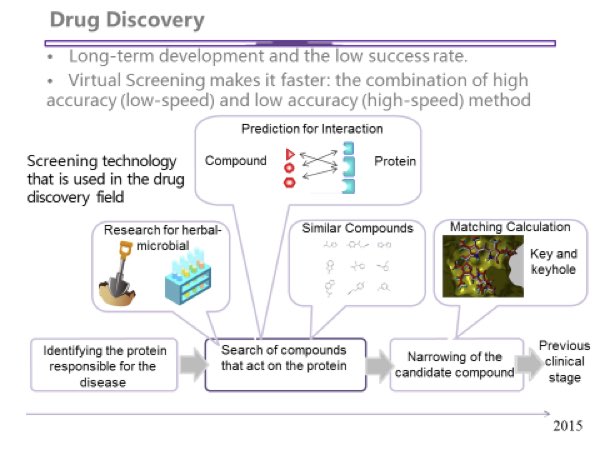
Figure 5: The case for virtual drug discovery lies in speed and volume. (Image courtesy Kyoto University)
“Since the DBN learns from the data it is possible that it can find drug candidates that do not resemble the structure of existing drug-like compounds,” Professor Okuno continued. “For this reason, we also think that deep learning can help find such de-novo drug candidates.”
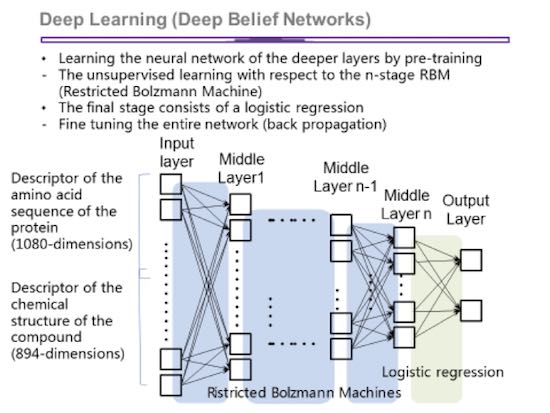
Figure 6: DBN can ‘learn’ features of the data that are important to drug-like activity. These DBNs can then be used to predict, or ‘score’ drug candidates. (Image courtesy Kyoto)
Big data is key to accurately training neural networks to solve complex problems. (In their paper, “How Neural Networks Work”, Lapedes and Farber showed that the neural network is actually fitting a ‘bumpy’ multi-dimensional surface, which means the training data needs to specify the hills and valleys, or points of inflection, on the surface. This explains why more data is required to fit complex surfaces.)
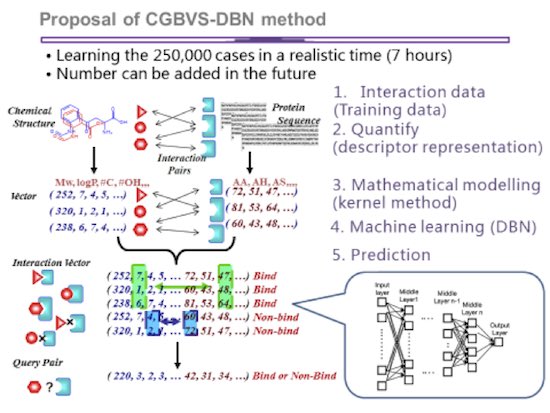
Figure 7: Proposed method to find drug candidates using deep learning (Image courtesy Kyoto University)
The Kyoto dataset evaluated the Theano scaling behavior to four million rows and 2,000 features. Results are validated using a 20% held out validation. In the future, the Kyoto team intends to use Theano to train on data sets with 200 million rows and 380 thousand features – a 130x increase in data!
“Experimental results are increasing day-by-day,” Professor Okuno said. “So we will always be looking to increase their computing performance.”
As can be seen below, the optimized multicore Theano code delivers excellent scaling as data set sizes increase, which allows training with much more data. The expectation is that the new Intel Xeon Phi processor-based system should scale similarly and deliver faster time-to-model performance.
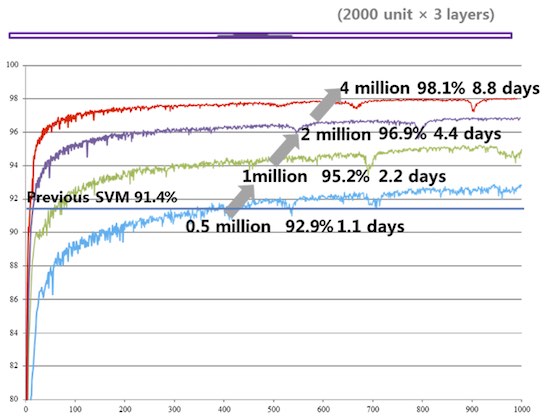
Figure 8: Scaling of optimized DBN Theano code according to data size. (Image courtesy Kyoto University)
Fixing poorly optimized multicore code compared to GPU code paths
The Kyoto results demonstrate that modern multicore processing technology now matches or exceeds GPU machine-learning performance, but equivalently optimized software is required to perform a fair benchmark comparison. For historical reasons, many software packages like Theano lacked optimized multicore code as all the open source effort had been put into optimizing the GPU code paths.
To assist others in performing fair benchmarks and to realize the benefits of multi- and many-core performance, Intel announced several optimized libraries at ISC’16 for deep and machine learning such as the high-level DAAL (Data Analytics Acceleration Library) and lower level MKL DNN libraries that provides optimized deep learning primitives. The ISC’16 MKL DNN announcement also noted the library is open source, has no restrictions, and is royalty free. Even the well-established Intel MKL (Math Kernel Library) is getting a machine learning refresh with the addition of optimized primitives to speed machine and deep learning on Intel architectures.
For example, the SGEMM operation is very important to machine learning algorithms, which heavily utilize single-precision arithmetic. The new libraries provide improved SGEMM parallelism.
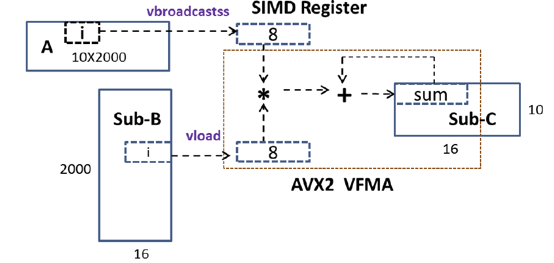
Figure 9: Improved SGEMM parallelism by AVX instruction along the contiguous address. (Image courtesy Intel)
The new vector and multicore optimized libraries announced at ISC’16 will speed machine learning efforts and assist others so they too – just like Kyoto University – can make fair comparisons using optimized multicore codes when evaluating hardware platforms for machine learning.
Expectations for the new Intel Xeon Phi processor-based cluster
The Academic Center for Computing and Media Studies (ACCMS) at Kyoto University will be standing up a new Intel Xeon Phi processor-based cluster designed to support training on the larger data sets. Specifically, the expectations are:
- To deliver higher performance so the team train on bigger data and in less time compared to other CPU and GPU platforms.
- To facilitate advanced algorithm development. Many deep-learning algorithms are complex, which means the Kyoto team wants to eliminate as many architecture limitations as possible. The consistent multi- to many-core programming environment is very attractive as it eliminates the complexities, memory limitations, and hardware variations of a GPU environment. Further, Intel has proven to be very responsive in providing optimized libraries that provide access to the Intel Xeon and Intel Xeon Phi capabilities.
Teaching people that multicore processors outperform GPUs
To help data scientists and the HPC community understand and use the multi- and many-core software and hardware technology, Intel has created a machine learning portal at http://intel.com/machinelearning. Content on this portal will teach readers how multi- and many-core processors outperform GPUs and deliver superior training and prediction (also called inference or scoring) performance as well as better scalability on a variety of machine learning frameworks. Through this portal, Intel hopes to train 100,000 developers in the benefits of their machine learning technology and optimized libraries. They are backing this up by giving early technology access to top research academics.
To help bring machine-learning and HPC computing into the exascale era, Intel has also created Intel Scalable Systems Framework (Intel® SSF). Intel SSF incorporates a host of software and hardware technologies including Intel® Omni-Path Architecture (Intel® OPA), Intel® Optane™ SSDs built on 3D XPoint™ technology, and new Intel® Silicon Photonics – plus it incorporates Intel’s existing and upcoming compute and storage products, including Intel Xeon processors, Intel Xeon Phi processors, and Intel® Enterprise Edition for Lustre* software.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology that he applies at national labs and commercial organizations throughout the world. He can be reached at info@techenablement.com.
[1] Broadwell microarchitecture improvements – especially to the FMA (Fused Multiply-Add) instruction – should increase performance even further. See http://www.nextplatform.com/2016/03/31/examining-potential-hpc-benefits-new-intel-xeon-processors/ for more information.


“NVIDIA K40 GPU using 16-bit arithmetic (which doubles GPU performance) ”
this is just plain wrong, the opposite is true
The K40 does not natively support FP16. However, people (Baidu, NVIDIA) do use it to achieve a performance benefit even on K40s. That comment should read ” (which can double GPU memory performance)”.