
In this special guest feature, James Reinders continues his series on programming the Intel Xeon Phi for HPC.

James Reinders, parallel programming enthusiast
In previous articles, I gave an overview with “Intel Xeon Phi Processor Programming in a Nutshell” of Intel’s 72-core processor often referred to as Knights Landing, and in “Intel Xeon Phi Memory Mode Programming (MCDRAM) in a Nutshell” plus “Intel Xeon Phi Cluster Mode Programming (and interactions with memory modes) in a Nutshell” I discussed the memory and cluster modes.
In this article, I discuss the use of the Intel® Advanced Vector Instructions (Intel® AVX-512), covering a variety of vectorization techniques available for accessing the performance of Intel AVX-512.
Intel AVX-512 – four topics to discuss
In our book, Intel Xeon Phi Processor High Performance Programming – Knights Landing Edition, we split out treatment of Intel AVX-512 vectorization into four topics, each of which will be introduced in this article with my thoughts on their relative merits. The four topics are:
- Vectorization
- Analysis and advice from a vectorization assistant tool
- A template library for vectorization
- Intel AVX-512 intrinsics
We did not really discuss the instruction set in our book because there are other resources for that. However, I will start with an introduction to Intel AVX-512 instructions in this article.
Intel AVX-512 overview
Intel AVX-512 is the latest in a long history of x86 vector instruction sets. Vector instructions, commonly known as SIMD instructions, are special because they do more than one operation at a time. For floating-point operations, 512-bits allow for 8 double precision (64-bits each) operations per instruction or 16 single precision (32-bits each) operations per instruction.
Intel Xeon Phi processor supports all prior SIMD (vector) instructions, namely Intel MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX and AVX2. The highest performance is always from Intel AVX-512 because it offers the most parallelism. Intel AVX-512 yields roughly twice the maximum performance over AVX/AVX2 (256-bit wide) and four times that of various SSE (128-bit wide) instruction sets.
Intel AVX-512, like AVX and AVX2, is designed more symmetrically to make it easier for compilers to target. Combined with some new features that make it more straightforward for compilers to target AVX than the more limited SSE or MMX instruction sets.
Intel AVX-512 features include 32 vector registers each 512 bits wide, known as ZMM0-ZMM31. It is interesting to note that the 32 ZMM registers represent 2K of register space! The AVX registers (YMM) map as the lower 256 bits of the ZMM registers, with the same support for SSE and MMX that prior AVX support included.
Two Intel AVX-512 features that help a great deal with compiler generated code and parallelism are: (a) controls “embedded” in Intel AVX-512 instructions that give instruction-by-instruction control over previously global concepts: rounding controls, broadcast, floating-point fault suppression, and memory fault suppression, and (b) eight dedicated mask registers for predication.
While Intel AVX-512 has defined groups, namely AVX-512 Foundation Instructions and AVX-512 Conflict Detection Instructions (CD), that are to be part of every AVX-512 implementation, there is room left for expansion. Intel Xeon Phi processors introduced the AVX-512 instruction set along with two AVX-512 instruction groups that are initially unique to Intel Xeon Phi processors, namely AVX-512 Exponential & Reciprocal Instructions (ER) and AVX-512 Prefetch Instructions (PF). Intel has documented that after this first AVX-512 appearance, future Intel Xeon processors will expand Intel AVX-512 with some additional subgroups for more integer and bit manipulation capabilities, namely AVX-512 Doubleword and Quadword Instructions, AVX-512 Byte and Word Instructions and Intel AVX-512 Vector Length Extensions. While these may appear in future generations of Intel Xeon Phi processors, they are not part of the current generation.
Vectorization
In practice, almost all use of Intel AVX-512 instructions will be produced by compilers, usually with hints from the programmer in the form of pragmas or directives. The hints are needed to overcome the historical lack of parallel-aware constructs in C, C++, and Fortran. These languages simply predate multicore and many-core processors, and therefore effective use of vector capabilities requires help from the programmer. Even with intrinsics, a compiler will actually output the precise AVX-512 instructions.
In all these ways, Intel AVX-512 is the same as prior vector instructions sets. The challenges and techniques are fundamentally the same but AVX-512 gives compilers more flexibility to perform optimizations that lead to higher performance.
The following program will not vectorize without some hints from the programmer; in this case, an OpenMP directive:
__declspec(align(16)) float a[MAX], b[MAX], c[MAX];
#pragma omp simd
for (i=0;i<max;i++)
c[i]=a[i]+b[i];
The reason it would otherwise not vectorize is that the C/C++ compilers must assume that parameters may overlap due to aliasing. Fortran does not have this problem, so this would not be an appropriate example of when to use such directives in Fortran.
There are many reasons why code may not vectorize. Parameter aliasing is just one of them. In the simple example, I used the OpenMP “simd” directive to tell the compiler to ignore the possibility of aliased parameters or any other barrier to vectorization. There are other ways to try to solve this problem. For instance, the C99 keyword “restrict” can be used in the parameter list. The “restrict” modification to the code will work if that is the only reason the code does not vectorize, which is true in our toy example. In more complex cases, the “simd” directive may clear up several barriers to vectorization.
In the prior book on the Intel Xeon Phi coprocessor, we covered vectorization as a single chapter. We added the other three topics in our book on Intel Xeon Phi processors based on encouragement from users for us to expand our treatment with more advice on what tools might help beyond the most popular option of using the compiler alone.
Analysis and advice from the Vectorization Assistant
Two popular questions are “why did this not vectorize?” and “is there more vectorization we could be getting?” The answers to these in the past have involved scanning compiler dumps and running performance analysis tools to compare with ‘back of the envelope’ calculations of theoretical peak performance
Some folks at Intel found a way to do better and created a tool called the “vectorization assistant.” It is part of a product called Intel® Advisor, which also does excellent thread/task analysis. An introduction to the tool exists online, and a trial version of the tool can be downloaded from Intel’s website (you may qualify for a longer-term free version if you are a student, educator, etc. – look for details on that page).
I like this tool, and how much it helps in a way that makes sense to me. We dedicated a chapter to this tool in our book. The general idea is simple: how much computation is a program doing and how close does it get to theoretical peak performance possible if all computations that could map to Intel AVX-512 instructions were being done by AVX-512 at full speed? We call this a “Roofline Analysis.” A couple of great papers about this technique are a paper from Berkeley and a paper from the Technical University of Lisbon.
Limitations in the ability to vectorize, limitations in the ability to fully feed the computation due to data layout, and various other issues may be addressable when we know we are falling short of our “Roofline.” On the other hand, when computation is seemingly at full performance there is no better vectorization to be had. We should not forget that we may still be able to find other computational approaches that need less computation!
A template library for vectorization
We have seen attempts at template libraries for vectorization before, but none have seemed to garner as much interest as the Intel® SIMD Data Layout Templates (SDLT). SDLT is available freely and is included with the Intel C++ compiler (free and purchased editions).
This template library allows code using an array of structures (AoS) interface to maintain their preferred programming style but with the benefits that come from better access patterns which are done “under the covers” by the template library. SDLT is about transforming a code with minimal changes from a bad data layout to a good data layout. An example of such a transform is on Intel’s site.
Intel AVX-512 intrinsics
We did not initially plan to include an explanation of intrinsics in our book. Fifteen years ago, I pushed the use of intrinsics like crazy as a much better option than programming in assembly language. In fact, intrinsics are just as powerful as assembly language but the compiler automatically handles interfacing with the rest of your program and integrating register usage smoothly with your C/C++ code. These advantages, combined with great compiler support for intrinsics from virtually all compilers, have made intrinsics a great success story.
Why did I not initially want to include them? I know that for almost everyone, the use of compiler hints along with regular code is effective, and much more portable. Intrinsics lock us into a specific instruction set. For instance, if I write code for Intel AVX using intrinsics, I will need to rewrite it to take advantage of Intel AVX-512. That is not true when we write in C/C++ and we let the compiler translate to whatever vector instructions we want.
What changed my mind? Two things: (a) seeing uses of them that were important, and (b) learning how much confusion there was among programmers not using them what intrinsics were and were not. Intrinsics are actually easy to learn and easy to use, and that was not widely understood. While I still think their use should be limited, they have their place and we can all benefit from understanding them.
The advantage of intrinsics is that the programmer does not have to write low-level assembly and also manage low-level instruction scheduling and register allocation, all of which is microarchitecture dependent and better handled by the compiler. Further, with intrinsics the compiler can generate better code such as fusing two SIMD instructions on platforms that support particular combinations.
To illustrate how easy intrinsics are to use, here is a simple example that loads two arrays containing 16 floating-point numbers and adds them together:
__m512 simd1 = _mm512_load_ps(a); // read 16 floats from memory
__m512 simd2 = _mm512_load_ps(b); // read 16 more floats
__m512 simd3 = _mm512_add_ps(simd1, simd2); // add them
Using intrinsics appears no different than calling a function. We simply include the header file for all AVX intrinsics (immintrin.h), and call the desired intrinsic function. As with other functions, we must observe the parameter and return types of the intrinsic function. Fortunately, there is extensive documentation on Intel’s site.
One of the mysterious things when you first use intrinsics is what the suffixes on the instruction mean. The suffixes seem to be something which you figure out when you look at enough instructions. Here is my decoder for common AVX-512 instructions:
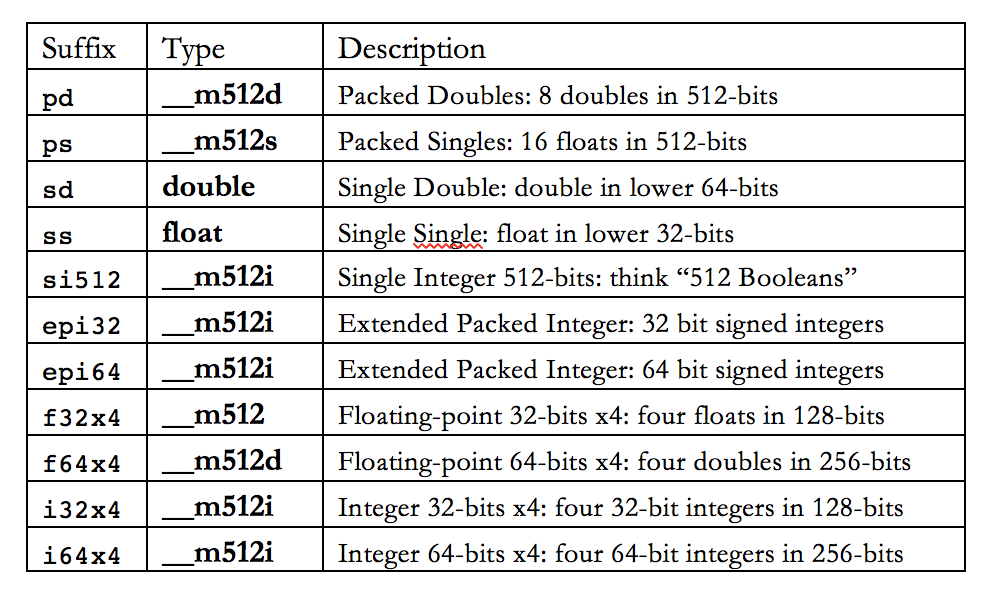
Educational Intel AVX-512 program
Here is a teaching example for Intel AVX-512 to help see how easy it is to use:
#include <stdio.h>
#include "immintrin.h"
void print(char *name, float *a, int num)
{
int i;
printf("%s =%6.1f",name,a[0]);
for (i = 1; i < num; i++)
printf(",%s%4.1f",(i&3)?"":" ",a[i]);
printf("\n");
}
int main(int argc, char *argv[]) {
float a[] = { 9.9,-1.2, 3.3,4.1, -1.1,0.2,-1.3,4.4,
2.4, 3.1,-1.3,6.0, 1.5,2.4, 3.1,4.2 };
float b[] = { 0.3, 7.5, 3.2,2.4, 7.2,7.2, 0.6,3.4,
4.1, 3.4, 6.5,0.7, 4.0,3.1, 2.4,1.3 };
float c[] = { 0.1, 0.2, 0.3,0.4, 1.0,1.0, 1.0,1.0,
2.0, 2.0, 2.0,2.0, 3.0,3.0, 3.0,3.0 };
float o[] = { 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0 };
__m512 simd1, simd2, simd3, simd4;
__mmask16 m16z = 0;
__mmask16 m16s = 0xAAAA;
__mmask16 m16a = 0xFFFF;
print(" a[]",a,16);
print(" b[]",b,16);
print(" c[]",c,16);
if ( _may_i_use_cpu_feature( _FEATURE_AVX512F ) ) {
simd1 = _mm512_load_ps(a);
simd2 = _mm512_load_ps(b);
simd3 = _mm512_load_ps(c);
simd4 = _mm512_add_ps(simd1, simd2);
_mm512_store_ps(o, simd4);
print(" a+b",o,16);
simd4 = _mm512_sub_ps(simd1, simd2);
_mm512_store_ps(o, simd4);
print(" a-b",o,16);
simd4 = _mm512_mul_ps(simd1, simd2);
_mm512_store_ps(o, simd4);
print(" a*b",o,16);
simd4 = _mm512_div_ps(simd1, simd2);
print(" a/b",(float *)&simd4,16);
printf("FMAs with mask 0, then mask 0xAAAA, ");
printf("then mask 0xFFFF\n");
simd4 = _mm512_maskz_fmadd_ps(m16z,simd1,simd2,simd2);
print("a*b+b",(float *)&simd4,16);
simd4 = _mm512_maskz_fmadd_ps(m16s,simd1,simd2,simd3);
print("a*b+b",(float *)&simd4,16);
simd4 = _mm512_maskz_fmadd_ps(m16a,simd1,simd2, simd3);
print("a*b+b",(float *)&simd4,16);
}
return 0;
}
Running this program on a machine with Intel AVX-512 gives the following output:

If you run on a machine without Intel AVX-512 support, only the first three lines will be printed. If you want to run the full program on a machine without AVX-512, Intel has a clever tool called the Intel® Software Development Emulator (SDE) that will let you run a program (already compiled) as if it was on a machine with other features (including AVX-512). Using the SDE, I have run the identical compiled program and printed identical output on an Intel Xeon Phi processor (with AVX-512) and on a machine without AVX-512.
Using intrinsics is not for everyone, and I think they should only be used if we cannot get a compiler to produce the code for us automatically. Solutions written in C/C++/Fortran that compile to efficient code are more portable and run on future hardware without needing new tuning. Increasingly, compilers are up to the task of vectorization, provided that we guide it around limitations in C/C++/Fortran. But, intrinsics give an alternative and allow for some clever programming too.
If you’ve not looked at intrinsics before, hopefully my little teaching program will inspire you give it a try. Feel free to start with the teaching program, and I do recommend Intel’s online guide for intrinsics very highly.
Summary
Intel Xeon Phi processors are remarkable x86 devices – featuring up to 72 x86 cores, and including numerous design features to allow very high performance usage as building blocks for the world’s most powerful supercomputers. Use of the Intel AVX-512 instruction set is vital to reaching the highest performance levels with the Intel Xeon Phi processor.
This is the fourth in a series of articles about Knights Landing. I started with an overview in “Intel Xeon Phi processor Programming in a Nutshell” of how to approach the second generation Intel® Xeon Phi™ processor often referred to as Knights Landing, followed by “Intel Xeon Phi Memory Mode Programming (MCDRAM) in a Nutshell” plus “Intel Xeon Phi Cluster Mode Programming (and interactions with memory modes) in a Nutshell.” Future articles will ponder other aspects of using Intel Xeon Phi processors.
Sign up for our insideHPC Newsletter


do you have this in Fortran, please?
Sadly, there is no support for SIMD intrinsics in Fortran compilers. An Intel engineer wrote “The SIMD intrinsic functions that are available to C and C++ developers do not have a corresponding Fortran interface, and in any case require a great deal of programming effort and introduce an undesirable architecture dependence.” His article outlines options in Fortran: https://software.intel.com/en-us/articles/explicit-vector-programming-in-fortran
I would add one to his list: put code needing intrinsics into a C file, compile and link with it. Trust me – I know this is not optimal for a Fortran code – but it is the best that I know of if you want to use intrinsics from Fortran.