
In previous articles (1 and 2) here on insideHPC, James Reinders described “Intel Xeon Phi processor Programming in a Nutshell” for Intel’s 72-core processor. In this special guest feature, he discusses cluster modes and the interaction of the memory modes with these cluster modes.

James Reinders, parallel programming enthusiast
Configuring to match the level of shared memory scaling
The default for Intel Xeon Phi processors is to give every processor core equal access to every part of memory including the MCDRAM. That is certainly great for programs that use shared memory across all the many cores (up to 72). However, the reality is that some applications may only scale their shared memory usage to 36 or 18 cores instead of 72. The architects of the Intel Xeon Phi processor included cluster modes as a way to take advantage of the characteristics of such programs using cluster modes (as I will explain in a bit, the key modes for such programs are SNC-2 and SNC-4 and I will also explain why the architects called them “Sub-NUMA Cluster” (SNC) instead of just NUMA).
Cluster applications generally use a shared memory programming model (e.g., OpenMP or TBB) coupled with MPI to scale across many processors (aka, nodes). Such applications may run 2, 4 or more MPI ranks on a single processor. Using cluster modes, the processor can be configured to take advantage of such application behavior. Specifically, the behavior that can be optimized for is the attribute of having very little memory sharing across hemisphere or quadrant boundaries. For instance, knowing that an application will run with 4 MPI ranks on a processor means that memory and cache accesses can be optimized for quadrants. Such an optimization reduces traffic across the mesh that interconnects the cores on the processor, and thereby reduces contention and latency. This can result in performance improvements for an application. Cluster modes do not specially need MPI to be used, but it is the likely reason for the behavior that SNC cluster modes optimize.
The selection of a cluster mode only affects performance, it does not change what an application may do. Every core/thread on the processor always has access to all memories and caches, coherency is always present.
Avoid Confusion: do not think about all the modes
Intel has built in a couple modes that are unlikely to be used in most systems. The first “unlikely to be used” mode is called All-to-All. The mode was included to support systems where the DDR is not installed symmetrically. While you might design a system this way in theory, the more likely scenario is that some DDR failed to pass on power-up but we still want the processor to be able to boot and help debug this. All other cluster modes are implemented efficiently because they can assume symmetric DDR. I suggest we simply ignore All-to-All for purposes of thinking about which cluster modes are interesting. The other “unlikely to be used” mode is called hemisphere. I say unlikely because the quadrant mode is probably better for every application. Hemispheres are more interesting in sub-NUMA modes (namely SNC-2) that I will discuss in the next section.
In my head, I think about the best cluster modes by answering three questions that I summarize in a decision tree at right.
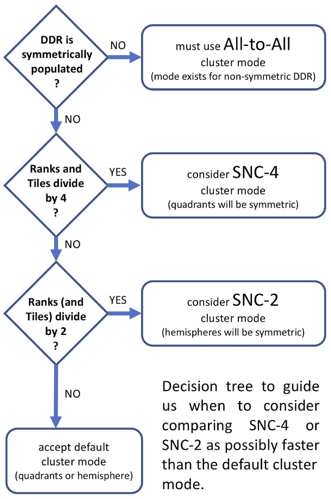
Regardless of our answers, the default of quadrant or hemisphere cluster mode will serve us well. Yes, technically the BIOS will force us to All-to-All when the machine can only support that (probably due to a DRAM chip failure). And, yes, we might see speedups from SNC modes in some situations. However, running in the default cluster mode is not a bad thing.
Sub-NUMA cluster modes (SNC)
The interesting part of cluster modes really comes down to the question of “Would we benefit from SNC-2 or SNC-4 instead of using the default quadrant mode?” It really is that simple. We really only need to test SNC-2 vs. quadrant, or SNC-4 vs. quadrant depending on how many MPI ranks we map onto the processors.
An aside: 72 divides by 4, but 68 does not
At first glance, you might assume my math is wrong. In reality, I could have been less provocative and pointed out that 72 divides by 8, but 68 does not. The thing to note here is that cores on Intel Xeon Phi processors come in pairs, called tiles, which cannot be split (they share a connection to the mesh and a piece of the L2 cache). When we talk about dividing the processor into hemispheres or quadrants, we really divide pairs of cores (tiles) in halves or quarters. 72 cores is 36 tiles, and that divides nicely into 18 tiles or 9 tiles. However, a 68 core device is 34 tiles, and that divides into hemispheres of 17 tiles, but into quadrants with 8 or 9 tiles each (two 8s, and two 9s).
This is what really makes “divides by two” possibly better than “divides by four.” On a 72-core device, if the number of ranks divides by four, then dividing into quadrant will be balanced and should be slightly higher performance than the modes which optimize around dividing into hemispheres. However, on a 68-core device, a division by two is balanced in the number of cores while a division by four is not. This makes it likely that a hemisphere division is more optimal on a 68-core processor.
Back to Sub-NUMA cluster modes (SNC)
The Intel Xeon Phi processor is a NUMA device when it has the most common configuration of having both MCDRAM and DDR and uses a memory mode other than all cache for the MCDRAM. Therefore, when subdividing the processor into hemispheres or quadrant with “SNC” modes the architects named these “sub-NUMA” modes to acknowledge that we might be already in NUMA mode even before using SNC.
I actually ignore MCDRAM/DDR induced NUMA in my head, when thinking about cluster modes, and I think of the default quadrant cluster mode vs. SNC-2/SNC-4 as a question of making the processor NUMA or not. Yes, this is technically incorrect… but it makes more sense in my head. Regardless of what makes the most sense to you, the non-SNC modes have a consistent latency to all MCDRAM and a consistent latency to all DDR, whereas the SNC modes induce “near MCDRAM” vs. “far MCDRAM” and “near DDR” vs. “far DDR.” The “near” portions have effectively lower latencies, and the “far” portions have effectively longer latencies. For an MPI program, with the appropriate number of ranks for the cluster mode selected – all application accesses will be “near” accesses as long as the “first touch” of the data comes from the MPI rank that will use the data which should normally be the case. The MPI library, will likely optimize message passing to happen in shared memory when the receiver and sender are on the same processor, and that will use far memory accesses for the transfers. The difference in timing is very slight, and only becomes apparent when many memory accesses are being done.
MCDRAM and DDR when in SNC modes
MCDRAM and DDR functionality does not change under the SNC modes, but the latency does and the way they map to NUMA nodes by the BIOS and subsequent operating system and library views does change.
The way it changes should be very familiar to anyone who has dealt with NUMA on a multiprocessor Intel Xeon processor based machine, or other modern multiprocessor machine. The penalties for NUMA on an Intel Xeon Phi processor are lower than multiprocessor systems because the divisions are among cores and caches on the same package.
In SNC-2 mode, half of MCDRAM and half of DDR will be “near” vs. “far” from a given hemisphere. In SNC-4 mode, three quarters of MCDRAM or DDR will be “far” from a given quadrant. This fits usage of the appropriate MPI applications precisely so any extra performance from the near/far should come without ill effects.
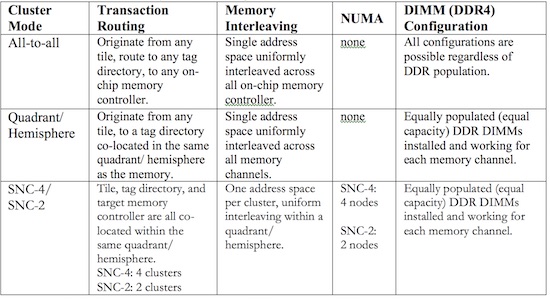
The performance benefits of SNC-2 or SNC-4 come from shorter paths from a requesting core to a potential hit in a part of the L2 cache, and to the memory when needed. These “transaction” routings stay within a hemisphere (SNC-2) or quadrant (SNC-4) for normal “near” accesses with the disadvantage of always being longer for “far” accesses. This unevenness is the “NUMA” effect which we see with all other systems with this many processor cores. The architects of the Intel Xeon Phi processor gave us the choice of modes to allow fitting to an application. The following table enumerates the cluster modes and their transaction routing with some notes about memory interleaving as well.
Summary
The Intel Xeon Phi processor may have up to 72 cores coupled with a versatile high bandwidth MCDRAM. Rather than only provide maximal performance for applications that scale their shared memory usage to all 72 cores, the processor can be configured to optimize for applications which scale their shared memory components to half or quarters of the processor and rely on MPI to connect these parts together. This division can come with a slight performance advantage without any change to our applications. We are simply matching the machine configuration to our applications instead of the other way around.
The MCDRAM remains usable as cache, high bandwidth memory, or a blend. However, with cluster modes it is also divided in a very logical manner that reflects how an application that focuses its shared memory utilization to hemispheres or quadrants would behave. Again, this allows the machine configuration to be set up to match the needs of the application. Finding the optimal configurations is as simple as changing some settings, rebooting and rerunning an application. This method of reconfiguration works with any operating system and application. In every configuration, the Intel Xeon Phi processor always remains a fully cache-coherent machine across all cores/threads and all memories/caches.
Thus far, I have described Intel’s 72-core processor with an overview in “Intel Xeon Phi processor Programming in a Nutshell”, and a look at memory modes in “Intel Xeon Phi Memory Mode Programming (MCDRAM) in a Nutshell,” and a look at cluster modes in this article. In my next article, I’ll tackle the very important vector capabilities of AVX-512. While AVX-512 is not unique to Intel Xeon Phi processors, it is where it first appears. The up-to-288 threads of Intel Xeon Phi processors coupled with the 16-element vectors of AVX-512, allow for a 4608-way parallelism overall when used together (288 x 16 = 4608). It is the threading combined with vectorization which yields this massive parallelism capability, and hence the importance of AVX-512.
All Figures are adopted from the book Intel® Xeon Phi™ Processor High Performance Programming – Intel Xeon Phi processor Edition, used with permission per lotsofcores.com.

