This sponsored post takes a look at Intel’s tools, like Intel VTune Amplifier, for improving application performance on the latest processors.
While the latest advances in processor architecture might promise enhanced performance for  compute-intensive applications, just upgrading to new hardware doesn’t always result in better application performance. It may take modifications to the code to reap those performance gains.
compute-intensive applications, just upgrading to new hardware doesn’t always result in better application performance. It may take modifications to the code to reap those performance gains.
Adding cores, increasing CPU speed, reducing memory latency, making vectors longer — all contribute to potential performance and efficiency gains with new processors. But in most cases, this potential is left on the table unless application codes are written (or re-written) to take advantage of these gains.
Code modernization means ensuring that an application makes full use of the performance potential of the underlying processors. And that means implementing vectorization, threading, memory caching, and fast algorithms wherever possible.
But where do you begin? How do you take your complex, industrial-strength application code to the next performance level?
In a recent issue of Intel® Parallel Universe magazine, researchers demonstrate how the tools in Intel® Parallel Studio XE helped them reduce the baseline performance of a typical finite difference application from 1,767 seconds down to 3 seconds with just a few basic code modifications.
[click_to_tweet tweet=”Code modernization means ensuring that an application makes full use of the performance potential of the underlying processors. ” quote=”Code modernization means ensuring that an application makes full use of the performance potential of the underlying processors. “]
They started with Intel® VTune™ Amplifier Application Performance Snapshot (APS) to get a quick profile of the application’s performance characteristics. This showed them the bottlenecks that were limiting performance. It also suggested which Intel Parallel Studio XE tools to use to add threading, vectorization, and to get better memory efficiency.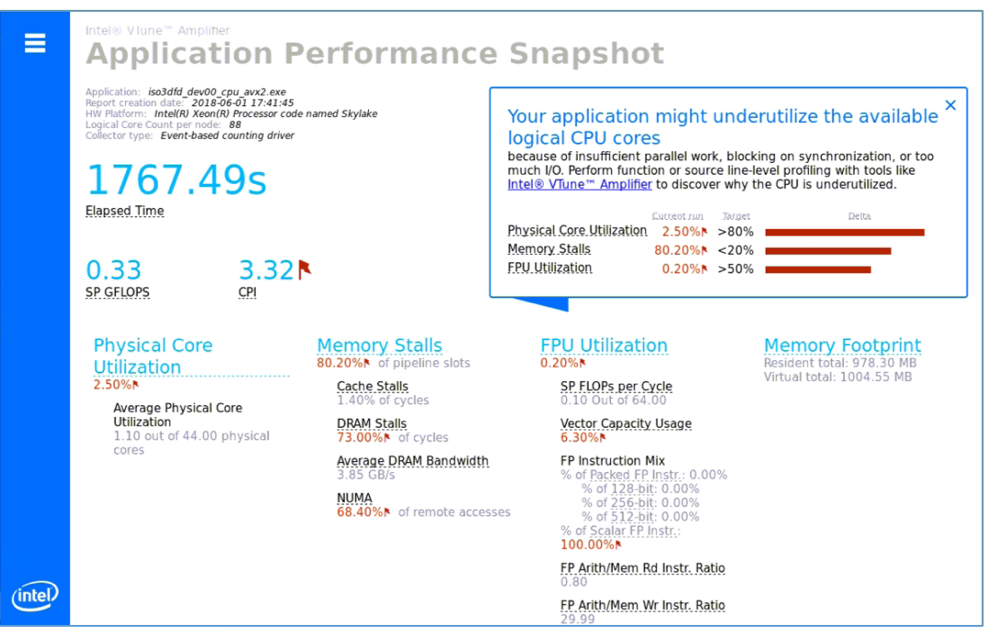
Using Intel VTune Amplifier, developers could identify the best places to add OpenMP* directives for threading the loops responsible for much of the execution time. This resulted in an immediate 38x speedup when running on a dual-socket 22 cores/socket processor.
Returning to APS revealed that the application was now memory bound. APS suggested running Intel VTune Amplifier Memory Access Analysis and then Intel Advisor Check Memory Access Patterns to detect which loops were causing the problem. By changing the loop order, access to array elements in the innermost loop became contiguous in memory, increasing cache reuse and gaining an additional speedup of about 4.7x.
APS now showed that OpenMP threading imbalances and memory stalls were causing significant performance issues. A deeper dive into Intel VTune Amplifier and Intel® Advisor succeeded to squeeze additional performance gains by suggesting changing the OpenMP scheduling scheme from static to dynamic, and by adding cache blocking techniques to the code.
Finally, APS pointed out low FPU utilization because most of the heavily used floating-point operations were scalar and not vectorized. APS suggested using Intel Advisor to find opportunities for vectorizing the code. Intel Advisor showed where inhibitors in loops prevented the compiler’s automatic vector code generation. Inserting the OpenMP omp simd pragma added extra performance speedups and improved FPU utilization by directing the compiler to vectorize those loops.
Using Intel Parallel Studio XE tools for code modernization, specifically Intel VTune Amplifier Application Performance Snapshot, you can achieve significant speedups on the latest processors with just a few basic code modifications. Using APS incrementally during the tuning process helps to quickly check optimization progress, while deeper analysis with Intel VTune Amplifier’s Memory Access and Intel Advisor’s Survey and Memory Access Patterns gain further speedups with caching and FPU vectorization.
For details on how, see Intel Parallel Universe #33: “Code Modernization in Action”
