Tim Miller, Vice President Strategic Development at One Stop Systems (OSS), highlights a new approach — ‘AI on the Fly’ — where specialized high-performance accelerated computing resources for deep learning training move to the field near the data source. One Stop Systems asserts moving AI compute to the data is another important step in realizing the full potential of AI.

Tim Miller, Vice President Strategic Development, One Stop Systems
The impact of artificial intelligence is starting to be realized across a broad spectrum of industries. Typically, deep learning (DL) training is a centralized datacenter process and inferencing occurs in the field. To build an AI system, data is collected, run through data scientist training models based on deep learning (DL) frameworks — on the fastest accelerated computers in the world — with the output sent to the field for an “AI at the Edge” system to inference from this model in day-to-day decision making.
To date, the vast majority of development and training of DL models across all industries occurs at private corporate IT rooms, institutional datacenters or hyperscale cloud computing centers. For typical “AI at the Edge” applications, an embedded computer, IoT device, intelligent camera or handheld device can handle simple AI inferencing tasks such as a phone performing speech translation. As the application becomes more complex and changes “on the fly”, such as how weather, construction, traffic and random events effect autonomous vehicles, an embedded “AI at the Edge” system simply performing inference of a pre-trained datacenter model could lead to safety concerns. To address these complex applications ‘AI on the Fly’™, where specialized high-performance accelerated computing resources for DL training move to the field near the data source, allows AI systems to inference, re-train and react to real-time changes in the environment “on the fly” — without sending the new data back to a centralized datacenter to create a new model.
Avoiding data movement over relatively slow or unsecure networks to remote datacenters also provides significant benefits in cost, responsiveness and security. By collocating data collection, DL training and predictive inference, developers of the most complex applications achieve real-time DL model refinement in the field. Where rapid response and continual learning are critical, the benefits of ‘AI on the Fly’ are clear; from autonomous vehicles, to personalized medicine to threat detection.
Figure 1 below shows how data originates from cameras or a wide array of sensors including radar, sonar, FLIR (infrared), LIDAR, RF tuners or MRIs. Data rates vary by protocols with multiple simultaneous channels, and the ingest subsystem must not inhibit the sensor data flow or allow data loss. For ‘AI on the Fly’ applications, real-time data rates are extremely high and require a combination of high speed data capture hardware and data storage. Multiple simultaneous FPGAs, frame grabbers, video capture, industrial IO and smart NICs with advanced features such as time stamping, encoding and filtering, can generate data in the 100s of Gbps.
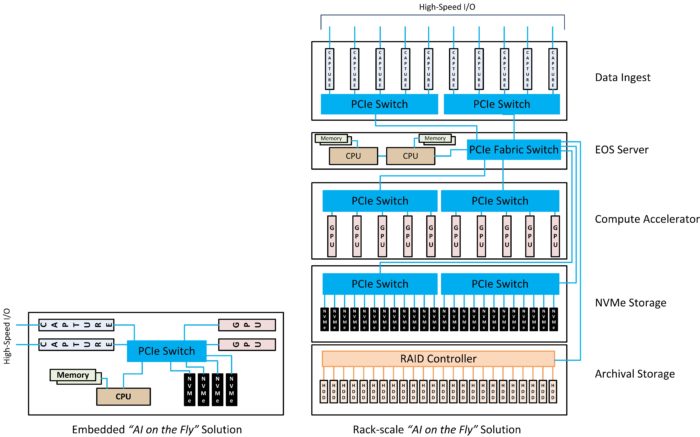
Figure 1: Embedded and Rack-scale “AI on the Fly” Systems. (Graph: OSS)
The high speed data must move to a persistent storage array supporting the same high speed throughput rate to the storage drives, while simultaneously moving data to the compute engines and archiving systems. Features in PCIe allow for simultaneous multi-casting the data to the multiple sub-systems, using RDMA transfers to avoid system memory bottlenecks without additional network protocol latency. Direct PCIe attached NVMe storage devices scale from 10TB to 1PB capacities to handle these requirements. Additionally, storage subsystems should include high availability, redundancy, security and support for removable storage media.
Moving AI computation to the data is another important step in realizing the full potential of AI.
The high performance compute subsystem forms the last major element in the ‘AI on the Fly’ solution. Depending on the scale of computing power required, the compute elements range from single compute nodes to several interconnected building blocks typically housing multiple GPU or FPGA accelerators. The compute functions include machine learning tasks using traditional data science tools; data analysis and query tasks using GPU Database tools and visualization; deep learning training tasks using neural network frameworks; or inference engines for prediction using trained models against newly sourced data. Each of these elements may require specialized GPU resources and support different levels of management and data scientist interaction. For example, in DL training data scientists prepare the data, select the models, evaluate the effectiveness of models after training runs and perform hyper-parameter tuning to increase model accuracy. For ‘AI on the Fly’, these functions are done remotely to keep the AI compute close to the data sources. For DL inference, results are real time with no human intervention. The critical requirements are responsiveness, accuracy and scaling to provide prediction on multiple streams of real time data.
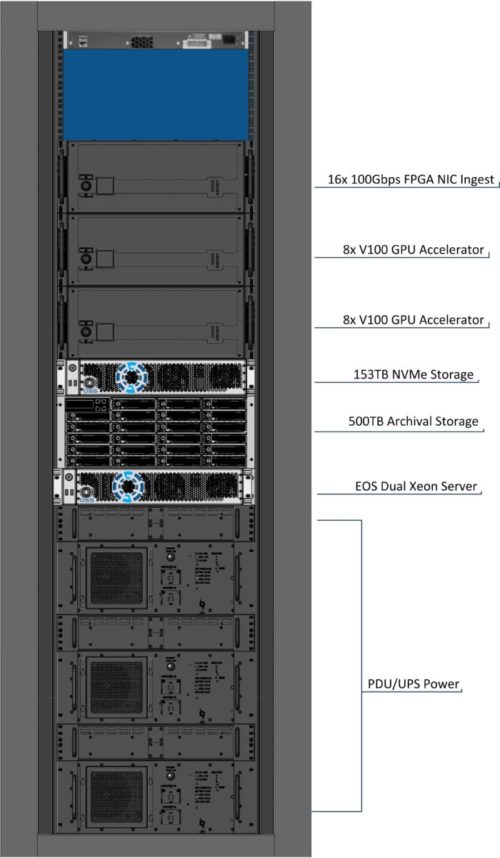
Figure 2: RF Spectrum Signal Recording and Analysis AI System (Image: OSS)
‘AI on the Fly’ solutions are different than traditional datacenter centric AI infrastructure, as they must deploy in harsh and rugged environments. The solutions must meet unique criteria for shock and vibration, redundancy, large operating temperature, altitude ranges and uninterrupted power sources. Few companies have the expertise across all the technologies required for designing and delivering tightly integrated ‘AI on the Fly’ platforms.
Figure 2 above shows an example of an ‘AI on the Fly’ rugged, modular, rack-level system housed in mobile shelters, which performs RF spectrum signal analysis for an ISR (intelligence, surveillance, reconnaissance) application with sustained ingest, processing and storage up to 24GB/s. The system includes PCIe FPGA-based signal acquisition cards directly interconnected with up to 400TB of high speed NVMe storage, 14.3 petaflops of GPU compute acceleration and an archival storage system from one dual processor server node.
Moving AI computation to the data is another important step in realizing the full potential of AI.
Tim Miller is Vice President of Strategic Development at One Stop Systems.
OSS has unique expertise in custom high speed PCIe system interconnect, scalable multi-GPU compute systems, high speed, low latency NVMe based storage systems and a long history of supplying rugged system to commercial, military and aerospace industries.
OSS’s ‘AI on the Fly’ solutions span from small deployments based on its range of Industrial Box PCs to very high-end systems based on multi-rack systems made up of ingest, compute, storage and accelerator building blocks.
Disclaimer: This article may contain forward-looking statements based on One Stop Systems’ current expectations and assumptions regarding the company’s business and the performance of its products, the economy and other future conditions and forecasts of future events, circumstances and results.

