DARPA is looking to create new networking approaches to accelerate distributed application performance by 100x with the FastNICs program.
Computing performance has steadily increased against the trajectory set by Moore’s Law, and networking performance has accelerated at a similar rate. Despite these connected evolutions in network and server technology however, the network stack, starting with the network interface card (NIC) – or the hardware that bridges the network/server boundary – has not kept pace. Today, network interface hardware is hampering data ingest from the network to processing hardware. Additional factors, such as limitations in server memory technologies, memory copying, poor application design, and competition for shared resources, has resulted in network subsystems that are creating a bottleneck within the network stack and are throttling application throughput.
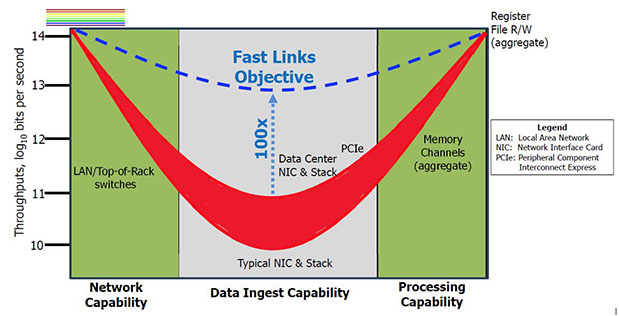
The true bottleneck for processor throughput is the network interface used to connect a machine to an external network, such as an Ethernet, therefore severely limiting a processor’s data ingest capability,” said Dr. Jonathan Smith, a program manager in DARPA’s Information Innovation Office (I2O). “Today, network throughput on state-of-the-art technology is about 1014 bits per second (bps) and data is processed in aggregate at about 1014 bps. Current stacks deliver only about 1010 to 1011 bps application throughputs.”
Addressing the bottleneck between multiprocessor servers and the network links that interconnect them is increasingly critical for distributed computing. This class of computing requires significant communication between computation nodes. It is also increasingly relied on for advanced applications such as deep neural network training and image classification.
To accelerate distributed applications and close the yawning performance gap, DARPA initiated the Fast Network Interface Cards (FastNICs) program. FastNICs seeks to improve network stack performance by a factor of 100 through the creation of clean-slate networking approaches. Enabling this significant performance gain will require a rework of the entire network stack – from the application layer through the system software layer, down to the hardware.
There is a lot of expense and complexity involved in building a network stack – from maximizing connections across hardware and software to reworking the application interfaces. Strong commercial incentives focused on cautious incremental technology advances across multiple, independent market silos have dissuaded anyone from addressing the stack as a whole,” said Smith.
To help justify the need for this significant overhaul, the FastNICs programs will select a challenge application and provide it with the hardware support it needs, operating system software, and application interfaces that will enable an overall system acceleration that comes from having faster NICs. Under the program, researchers will work to develop, implement, integrate, and validate novel, clean-slate network subsystems.
Part of FastNICs will focus on developing hardware systems to significantly improve aggregate raw server datapath speed. Within this research area, researchers will design, implement, and demonstrate 10 Tbps network interface hardware using existing or road-mapped hardware interfaces. The hardware solutions must attach to servers via one or more industry-standard interface points, such as I/O buses, multiprocessor interconnection networks, and memory slots, to support the rapid transition of FastNICs technology. “It starts with the hardware; if you cannot get that right, you are stuck. Software can’t make things faster than the physical layer will allow so we have to first change the physical layer,” said Smith.
A second research area will focus on developing system software required to manage the FastNICs hardware resources. To realize 100x throughput gains at the application level, system software must enable efficient and parallel transfer of data between the network hardware and other elements of the system. FastNICs researchers will work to generate software libraries – all of which will be open source, and compatible with at least one open source OS – that are usable by various applications.
FastNICs will also explore applications that could be enabled by the multiple order of magnitude performance increases provided by the program-generated hardware. Researchers will aim to design and implement at least one application that demonstrates a 100x speedup when executed on the novel hardware/software stack, providing a validator for the program’s primary objective. There are two application areas of particular interest – distributed machine learning and sensors. Machine learning requires the harnessing of clusters – or large numbers of machines – so that all cores are employed for a single purpose, like analyzing imagery to help self-driving cars appropriately identify an obstacle in the road. “Recent research has shown that by speeding up the network support, the entire distributed machine learning system can operate more quickly. With machine learning, the methods typically used involve moving data around, which creates delays. However, if you can move data more quickly between machines with a successful FastNICs result then you should be able to shrink the performance gap,” said Smith.
FastNICs will also explore sensor data from systems like UAVs and overhead imagers. An example application would be change detection where tagged images are used to train a deep learning system to recognize anomalies in a time series of image captures, such as the presence of a strange structure, or a sudden spurt in activity at facilities in an inexplicable location. Change detection requires quick access to both current sensor data as well as the ability to rapidly access archives of data. FastNICs will provide a way of accelerating the acquisition of actionable intelligence from a mountain of data.
Source: DARPA

